Insights
Far from being mere spectators, we’re active participants shaping what comes next. Dive into our thoughts on innovation, human ingenuity, technology, productivity, and corporate culture. Here’s what we have to say.
Osedea and Mila announce a new partnership to contribute to AI adoption and innovation in Quebec
%20(1).jpg)
Montreal, April 10, 2024 - Mila is proud to announce a new strategic partnership with Osedea. Together, they look forward to combining their expertise to contribute to Quebec's technology ecosystem and promote companies’ adoption of AI.
This collaboration will provide Osedea with access to Mila's cutting-edge research, consolidating its place as a major player in digital transformation in Quebec. In addition, by recruiting interns from Mila's student and research teams, and by participating in hiring events organized by Mila, Osedea will strengthen its team and its commitment to innovation. Together, they aim to contribute to Quebec's dynamic ecosystem of technological innovation and AI talent development. This partnership underscores Osedea and Mila's shared commitment to innovation, excellence and the training of skilled workers in technology.
"We are delighted to partner with Mila in this move to stimulate technological innovation in Quebec," said Martin Coulombe, President of Osedea. This partnership will enable us to reinforce our leadership in software engineering while actively contributing to the advancement of AI to improve the productivity of our companies in the manufacturing, mining and healthcare sectors. Together, we are determined to create a positive and lasting impact in the field of technology."
“Mila is very pleased to welcome Osedea to its community of partners. With this partnership, we look forward to connecting Osedea with Mila’s world-class researchers and AI talent in order to work towards our shared goal of supporting AI adoption and innovation in Quebec,” said Stéphane Létourneau, Executive Vice President of Mila.
About Mila
Founded by Professor Yoshua Bengio of the University of Montreal, Mila is the world’s largest academic research center for deep learning, bringing together over 1,200 specialized researchers in machine learning. Based in Montreal and funded in part by the Government of Canada through the Pan-Canadian AI Strategy, Mila's mission is to be a global center for scientific advancements that inspire innovation and the growth of AI for the benefit of all. Mila is a globally recognized non-profit organization for its significant contributions to deep learning, especially in the fields of language modeling, automatic translation, object recognition, and generative models.
About Osedea
Osedea is a Montreal-based innovation firm specializing in the creation of customized technological solutions for businesses. Founded in 2011, Osedea distinguishes itself through its expertise in artificial intelligence, robotics, software engineering and user experience design (UX/UI), in addition to its approach focused on innovation and collaboration with its customers. To find out more, visit www.osedea.com.
Navigating the nexus of tech and industry at Hannover Messe 2024
For the second consecutive year, I had the opportunity to attend Hannover Messe, the world's largest manufacturing and technology trade show. The 2024 edition presented some notable differences from 2023, namely Canada’s more prominent presence, with booths spread across four halls and plenty of promotion surrounding the nation’s upcoming role as partner host country for 2025.
Having learned from my experience at last year's show, I was better prepared to navigate the vast exhibition halls—where many exciting things take place at the same time—and make the most of my time. Here are my key takeaways.
Our project showcased on the world’s biggest stage
We’re proud collaborators on Promark Electronics’ intelligent KonnectAi project, an in-process and final visual quality inspection system powered by state-of-the-art computer vision algorithms and technology. To celebrate its monumental launch, our client Jarred Knecht (president of Promark and KonnectAI) took center stage to champion AI accessibility and demo KonnectAi at the Google Cloud booth (the cloud partner driving the technology). It was a powerful experience and an unmatched opportunity for this new innovation to attract new business.


Go digital, become sustainable
ClimateTech and sustainability were ubiquitous themes at the event. Once again this year, Siemens spearheaded these efforts, showcasing an array of cleanTech and potential solutions throughout their space. Remarkably, they boasted the largest and most impressive booth at all of Hannover Messe. Here’s a fun fact: it costs Siemens a staggering 32 million dollars annually to assemble and maintain this booth, which also serves as a year-round fixed showroom.
Primarily, Siemens highlighted three key solutions to address the climate change crisis: their EcoTech products, sustainable factories, and comprehensive sustainability solutions. These initiatives align with Siemens’ vision of achieving carbon neutrality globally by 2030. From employing digital twins to recycling tires within a circular economy, a plethora of innovative technologies were displayed to support this goal.
A standout example of these sustainable solutions is PlantSwitch, a startup using Siemens technologies to transform plants into plastics. The beauty of this innovation is that all the end products are compostable. In total, Siemens has developed 37 EcoTech products, seven of which were featured at Hannover Messe.

AI and XR everywhere
This year again, AI was omnipresent. It’s clear that companies not currently investing or considering leveraging AI to enhance their efficiency will likely find themselves at a disadvantage in the future. As Jarred Knecht recommended, he urges all manufacturing companies to initiate their AI journey with a small project. Often this represents a minimal investment for companies, thanks to various support programs offered to manufacturing companies such as SIPEM, IRAP, and ESSOR, just to name a few.
One standout company at the event was iGus, who expertly melded AI with sustainability. By integrating technology and AI, they’ve succeeded in eliminating lubricants from engines—a crucial innovation since just one liter of lubricating oil can contaminate a million liters of drinking water.
I also had the opportunity to try the new Meta Quest XR helmets. Once again, XR technologies have taken a significant leap forward this year! It’s remarkable how user-friendly this technology has become for manufacturing and design companies. XR enables engineers and designers to prototype and visualize products in a virtual space, enhancing collaboration and expediting the iteration process before physical production. This not only streamlines the design process, but also significantly reduces time-to-market.

Future unveiled
In conclusion, if you have a keen interest in industrial technology, automation, R&D, and want to be blown away by future possibilities, Hannover Messe is an unmissable event. For Canadian companies, the 2025 edition holds particular significance, as Canada will be the honoured partner host country. This special role will feature a central pavilion showcasing over 200 leading Canadian organizations, alongside daily conference programming that includes product and technology presentations on stage. This will be a prime opportunity for Canada to highlight its industrial and technological innovations, fostering new partnerships and shaping future industries.

See you in 2025!
Embracing clarity and structure: adopting the C4 model for software architecture diagrams

In the ever-evolving landscape of software development, our Software Design and Quality Team (SDQT) at Osedea is continuously seeking ways to refine our development workflows. Each month, we gather to engage in deep discussions about the latest and emerging trends in technology. From delving into modern trade-off analyses in distributed architectures to keeping updated with new tools and frameworks, we strive to maintain agility in our software development life cycle. This article explores the advantages of the C4 model in technical communication, highlighting its descriptive approach, use of contrasting colors, and ability to streamline the documentation process. Additionally, it offers practical tips for getting started with the C4 model and underscores its transformative impact on presenting technical aspects of projects to clients.
A few months ago, we introduced the C4 model by Simon Brown into our discussions. After experimenting with the model on various occasions, we quickly realized that this model should become a standard in our approach to creating architectural diagrams. The transition from our traditional methods to this new approach wasn't just a change in technique, but a significant shift in how we perceive and communicate complex system designs.
What is the C4 model?
The C4 model, based on the 4+1 architectural view model, can be compared to a multi-layered map for software architecture. It allows us to view a system at various levels of abstraction, similar to how you might navigate Google Maps - from an aerial view of the world down to individual streets and buildings. In C4, each “C” represents a different type of model at a different level of detail. These different levels are known as context, containers, components, and code:




Context: This is the highest level of the model, providing a big-picture view of the system. It shows how the software system interacts with its users and other systems. This is essential for understanding the system's boundaries and its relationships with external entities. This level is meant to be suitable for all stakeholders including non-technical users.

Containers: At this level, the focus shifts to the applications and data stores (like databases, file systems, etc.) that comprise the system. It illustrates how these containers interact with each other and the responsibilities they have within the system. This level is crucial for understanding the high-level technology choices and how the system is structured.

Components: This level breaks down the containers into their constituent components, detailing the responsibilities of these components and how they interact with one another. It's useful for developers and others involved in the build and design process, as it provides a more detailed view of the system's architecture.

Code: The most granular level, focusing on the individual classes and interfaces that make up the components. This level is particularly relevant for developers who need to understand the internal structure and design of the various components in detail. Most IDE’s have tooling available to generate these diagrams.
At this point, I’m sure you’re wondering why code is part of an architectural diagram. The beauty of this model is that you choose at what level of granularity you want to stop. Most of the time, the code portion is left out of these diagrams. For client presentations, we’ve found that the first and second layer is just right to convey a detailed overview of the architecture. The third layer comes in handy before the implementation phase to plan out the finer details.
What are the advantages of the C4 model?
At its core, the C4 model addresses a fundamental issue in technical communication: the conveyance of information. Often, technical diagrams are cluttered with technology-specific icons, which, while informative to some, can be perplexing to others—the C4 model advocates for a more descriptive approach. Instead of relying on symbols that might be familiar to only a subset of the team, it encourages explanations of what each technology does. This approach ensures that everyone, regardless of their familiarity with specific technologies, can understand the architecture.
The C4 model also emphasizes the use of contrasting colors instead of relying solely on color codes, making diagrams comprehensible even when printed in black and white. This consideration ensures that the diagrams remain effective and clear under different viewing conditions, including digital displays and physical printouts.
Additionally, the C4 model streamlines the documentation process, providing a clear and concise framework. This is particularly beneficial for complex systems where detailed documentation is crucial. By delineating different layers of the system, from the context down to the code level, the C4 model aids in creating comprehensive and structured documentation that can be easily understood and maintained.
How to get started with the C4 model?
In terms of tools for designing C4 diagrams, tools like Structurizr and Mermaid.js, which support the "C4 model as code" approach are often recommended. This method is advantageous during the development phase as it facilitates easy maintenance and updates to the diagrams. While C4 as code is preferred for its automated and maintainable approach, we’ve noticed that other tools like draw.io can also be beneficial. Despite being manual and potentially tedious, draw.io enables the creation of aesthetically pleasing diagrams that are well-suited for client presentations.
Implementing the C4 model has transformed how we present technical aspects of projects to our clients. It empowers them to choose the level of detail they wish to engage with. This flexibility enhances their understanding and allows for more meaningful discussions about the project.
As we move forward, our commitment at Osedea is to integrate the C4 model into all our architectural processes. We believe this approach will enhance our efficiency and clarity in software design. Keep an eye on future updates and insights from our SDQT team as we steadily progress in the ever-changing technology landscape. For those interested in evolving their software architecture or seeking guidance in modern development methodologies, Osedea is here to assist. Feel free to reach out for a discussion on how we can support your software development goals with our expertise and experience.
Osedea portraits: AI, adventure and culture with Isabelle Bouchard

As part of our Osedea Portraits series, meet Isabelle Bouchard, senior developer and machine learning specialist. Driven by an insatiable curiosity, Isabelle passionately explores the world of AI and its applications for the well-being of all. Beyond her sharp expertise, discover a sparkling and inspiring woman who will share with us her passions and the many facets of her personality.
Where does your interest in science and artificial intelligence come from?
It was a bit by chance (or luck!) that I decided to pursue a career in artificial intelligence. Initially, I studied biomedical engineering. At the end of my studies, although I had an interest, I had very little experience in software development, and even less in artificial intelligence. In truth, I'd never even heard of the concept of machine learning (ML) until I explored its techniques in my first job.
I immediately liked the fact that it required both mathematical and software development skills, as well as a good ability to break down a problem. I did a bit of self-study, supported by colleagues who helped me progress a lot. I then decided to do a master's degree to formalize my learning and develop research experience.

What are you most passionate about in AI?
I particularly appreciate the dynamism of this field, which evolves very quickly. I am constantly challenged and I have to learn continuously to be able to stay up to date with the technologies.
Moreover, the applications of AI are endless, which allows me to explore new application domains. In recent years, I have worked on projects in health, agriculture, urban planning, and many other areas. It is extremely stimulating.
In cutting-edge sectors such as artificial intelligence, women represent only 22% of professionals. In addition, women represent only 28% of engineering graduates and 40% of computer science graduates. What do you think explains the low number of women in technology, engineering, and artificial intelligence?
There are many reasons why women choose fields other than technology, but it is clear to me that the lack of female role models is one that weighs heavily in the balance. This also explains why many women choose to leave the field, where they do not always feel at home. We naturally develop affinities with people who resemble us, so it can sometimes be more difficult to find allies or mentors when you are a woman in an environment that is predominantly male. We also have a fairly well-defined preconceived idea of the typical developer, and it can be scary when you don't identify with it. Personally, it affected me for a long time, but I learned over time to recognize that, clearly, I will never fit that profile, but that it is more often seen as a strength than a weakness.
How do you see the impact of AI and machine learning on industries in the years to come, especially in areas such as healthcare, finance, and technology?
I hope to see AI assist humans, rather than replace them, especially in healthcare. Our systems are increasingly lacking in humanity, and I hope that our leaders will be able to understand how to use technologies to make us more efficient, but without losing sight of the importance of human relationships. You will understand that I am not necessarily the optimistic type! AI and technology in general offer endless possibilities, but we still need to know how to use them wisely.
How does the AI team at Osedea integrate ethical principles into the design and deployment of AI-based solutions?
The ethics of AI projects still largely depends on the people who develop them. So I would spontaneously say that it all starts with hiring people who have these issues at heart. Then, in our process of analyzing the needs of a project, we have several checkpoints to ensure that we raise and mitigate the main ethical risks. For example, we analyze the datasets used to train our AI models to ensure that we do not favor one segment of users over an underrepresented group in the data.
What would be your ideal retirement?
A healthy one! I love the outdoors. I would like to have a retirement filled with adventures that would allow me to continue to push myself physically and mentally, and to marvel at nature. All this accompanied by my favorite adventure partner, our family and friends... and of course, interspersed with good moments of relaxation!

Do you have a favorite movie or book to recommend, and why?
Fresh from the Oscars, I can't recommend the sublime film "Poor Things" highly enough, starring the incredible Emma Stone. Like all of Yorgos Lanthimos' films, it stands out for its intricate screenplay and utterly unsettling characters. A true gem!
I also highly recommend reading the classic American novel "The Grapes of Wrath" by John Steinbeck. Published in 1939, this novel tells with great accuracy and enduring relevance the human experience of those who lose the life lottery and find themselves in poverty. A deeply moving story.
What is your best and worst habit?
My best habit is to be active. It's a constant effort, but it's so beneficial to me that I make it a daily priority. My worst habit...procrastinating, without a doubt, but I'm working on it!

What's your best trip and why?
It was a trip to Turkey, in 2015, when I had just finished my university degree. I loved the rich culture, the grandiose landscapes and the absolutely vibrant cities, but above all, the incredible sense of freedom I was lucky enough to experience while traveling in my early twenties. With no money and no time constraints, we really let ourselves be carried along by the encounters and opportunities that came our way. I know I'll never be able to do that again - it was magical!

If you could instantly possess one skill, what would it be and how would you use it in your daily life?
I would love to have the ability to speak fluently and confidently on the spot, in a clear and concise manner. I truly admire people who can do this naturally! I would apply this skill in all areas of my life, both personally and professionally. Communication is so important in all of the relationships we have. It would be magical to be able to do this in multiple languages!
Transforming Vertical Farming with the Spot Robot at Interius Farms

The Context
In pursuing innovation and sustainable practices, Interius Farms, a leader in AgTech innovation, partnered with Osedea to explore the potential of dynamic sensing and mobile robotics in vertical farming. This collaboration aims to bring efficiency, automation, and precision to growing leafy greens and herbs while prioritizing environmental responsibility.
The Power of Advanced Robotics and AI in Vertical Farming
Interius Farms is at the forefront of innovation in agriculture, utilizing advanced technology to revolutionize traditional farming practices. By leveraging Osedea's mobile sensing platform, the Spot robot, they can integrate advanced robotics and AI into their operations. The Spot robot navigates the farm autonomously, collecting data and monitoring plant health using its sensors. This dynamic sensing mission allows for around-the-clock precision tasks and ensures accurate data collection, eliminating the need for manual and error-prone practices.

Creating a Sustainable Future with Hard Tech
Interius Farms' commitment to sustainability aligns perfectly with Osedea's vision for a brighter future. By implementing advanced technologies like robotics, AI, and data analytics, Interius Farms maximizes efficiency and minimizes resource consumption. Through their hydroponic system, they use 95% less water and 92% less land than traditional agriculture. Additionally, their controlled environment and optimized lighting systems reduce energy consumption, making their vertical farm more energy-efficient.
Osedea's Role in the Digital Transformation of AgTech
Osedea brings more than just software delivery to the table. As a solutions provider, we understand businesses' unique needs and challenges in the industrial sectors like AgTech. Our expertise lies in crafting custom software solutions tailored to meet specific requirements. By combining our proficiency in robotics, AI, and data analytics, Osedea enables businesses to achieve digital transformation and unlock the full potential of technological advancements. Their focus on usability, innovation, and fresh concepts pushes the boundaries of what digital efficiency can do for the AgTech industry.

What's Next
The deployment of Osedea's Spot robot at Interius Farms is a significant step towards revolutionizing vertical farming. Interius Farms can achieve enhanced efficiency, productivity, and sustainability by integrating advanced robotics, AI, and custom software solutions. The collaboration between Interius Farms and Osedea demonstrates the power of partnerships and research-driven innovation in driving positive change. By embracing hard tech and leveraging the transformative capabilities of advanced robotics and AI, businesses like Interius Farms are pioneering new paths toward a more sustainable future. The combination of vertical farming, AgTech, robotics, and AI empowers leaders to become data architects, enabling them to make informed decisions and optimize their operations.
As we look ahead, it is clear that continued collaboration and the strategic application of cutting-edge technologies will fuel further advancements in the AgTech industry. Interius Farms and Osedea are shaping the future of agriculture, one breakthrough at a time, and nurturing a world where innovation and sustainability go hand in hand.
A minimalist approach to DataOps and MLOps with DVC and CML
In this article, we'll look into the critical importance of DataOps and MLOps in software and AI development. We will showcase a hands-on MVP approach, emphasizing the use of DVC (Data Version Control) and CML (Continuous Machine Learning), integrated with Git, to illustrate these concepts effectively.
- Practical Approach: Using DVC and CML, we demonstrate a real-world, minimal viable product (MVP) approach to DataOps and MLOps.
- Integration with Git: Highlighting the seamless integration of these tools with Git, we show how familiar workflows can be enhanced for data and model management.
- Effective Implementation: Our goal is to provide clear guidance on effectively implementing DataOps and MLOps practices.
Common Issues in AI & Data Projects
- "Which Data Version?"Are you constantly losing track of the data version used for model training?
- "Is the New Model Any Good?"Stop wondering if your latest model beats the old one or what changed between them.
- "Why's Our Repo So Heavy?" Bloated GitHub repository with data?
What is Understanding DataOps and MLOps
DataOps and MLOps are foundational practices for modern software development, particularly in AI. These approaches are essential for effectively managing the data and machine learning model lifecycles.
- Scalability: Efficiently managing data (DataOps) and machine learning models (MLOps) is critical to building scalable and robust AI systems, crucial for software development projects.
- Performance and Reliability: Implementing these practices ensures consistent system performance and reliability, which is especially vital for startups operating in dynamic and resource-constrained environments.
- Pitfalls to Avoid: Many development teams need to correctly version data and models or take a reactive approach to system management, leading to significant challenges in reproducibility and increased error rates, hindering growth and innovation.
Understanding and integrating DataOps and MLOps into workflows is not just beneficial; it's a strategic necessity.
The MVP Approach
The MVP (Minimal Viable Product) approach in DataOps and MLOps is all about aligning with the core principles of the Agile Manifesto, emphasizing simplicity, effectiveness, and deployment.
- Agile Principles: Emphasize simplicity, effectiveness, and people-first processes, promoting flexibility and responsiveness in project management.
- Reducing Dependency on Complex Systems: Advocate for minimizing reliance on complex SaaS and proprietary systems, thus maintaining control and flexibility in your development.
- Effective Tools: Leverage tools like DVC and CML that integrate with familiar Git workflows; this approach ensures seamless adoption and enhances team collaboration and efficiency.
Adopting an MVP approach means creating more agile, adaptable, and efficient workflows in DataOps and MLOps, allowing for the development of robust and scalable solutions without getting bogged down by unnecessary complexities.
Hands-On
Now, we dive into the practical aspects of setting up a Python environment and using essential tools like DVC, CML, and SciKit-Learn. We'll go through configuring a GitHub repository for effective version control and demonstrate building and evaluating a model using SciKit-Learn in a Jupyter Notebook.
- Setup: Set a Python environment and install DVC, CML, and SciKit-Learn.
- Model Building: Use SciKit-Learn with a built-in dataset in a Jupyter Notebook for a simple model training and evaluation demonstration.
- Streamlined Process: Configure GitHub and Git to execute and assess your model.
Install Python Environment
We'll use Poetry to manage our Python environment. Poetry is a Python dependency management tool that allows you to create reproducible environments and easily install packages.
# Install Poetry
pipx install poetry
# Init Poetry project
poetry init
# Add dependencies
poetry add dvc cml scikit-learn
Loading the Data
We'll use the Breast Cancer Data Set from the UCI Machine Learning Repository.
Key characteristics:
- Number of Instances: 569.
- Number of Attributes: 30 numeric, predictive attributes, plus the class.
- Attributes: Measurements like radius, texture, perimeter, area, smoothness, compactness, concavity, concave points, symmetry, and fractal dimension.
- Class Distribution: 212 Malignant, 357 Benign.
import sklearn.datasets
# Load dataset
data = sklearn.datasets.load_breast_cancer(as_frame=True)
print(data.data.info())
Implementing External Settings for Data and Model Adjustments
We'll use external configuration files, like settings.toml, to dynamically adjust data and model parameters. This approach adds flexibility to our project and underscores the importance of versioning and tracking changes, especially when introducing intentional alterations or "bugs" for demonstration purposes.
Degrading the Data with External Settings
Because the demonstration dataset performs well with a simple model, we'll artificially degrade the data to emphasize the importance of tracking changes and versioning.
- External Configuration: Utilize settings.toml to set parameters like num_features=1, which dictates the number of features to be used from the dataset.
- Data Manipulation: We dynamically alter our data by reading the num_features setting from settings.toml. For instance, reducing the dataset to only one feature:
python
import toml
settings = toml.load("settings.toml")
data.data = data.data.iloc[:, : settings["num_features"]]
print(data.data.info())
Training the Model
We'll use SciKit-Learn to split the data and train a simple model.
python
import sklearn.model_selection
# Split into train and test
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
data.data, data.target, test_size=0.3, random_state=42
)
python
import sklearn.linear_model
# Train a simple logistic regression model
model = sklearn.linear_model.LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
python
# Evaluate the model
predictions = model.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(y_test, predictions)
print(f"Model Accuracy: {accuracy:.2f}")
Model Accuracy: 0.91
python
# View the classification report
report = sklearn.metrics.classification_report(y_test, predictions)
print(report)
# Export the report to a file
with open("report.txt", "w") as f:
f.write(report)
precision recall f1-score support
0 0.93 0.83 0.87 63
1 0.90 0.96 0.93 108
accuracy 0.91 171
macro avg 0.92 0.89 0.90 171
weighted avg 0.91 0.91 0.91 171
python
import seaborn as sns
import matplotlib.pyplot as plt
# Create a confusion matrix
confusion_matrix = sklearn.metrics.confusion_matrix(y_test, predictions)
# Plot the confusion matrix
sns.heatmap(confusion_matrix, annot=True, fmt="d")
# Export the plot to a file
plt.savefig("confusion_matrix.png")
Saving the Model and Data
We'll save the model and data locally to demonstrate DVC's tracking capabilities.
python
from pathlib import Path
# Save data
Path("data").mkdir(exist_ok=True)
data.data.to_csv("data/data.csv", index=False)
data.target.to_csv("data/target.csv", index=False)
python
import joblib
# Save model
Path("model").mkdir(exist_ok=True)
joblib.dump(model, "model/model.joblib")
Implementing Data and Model Versioning with DVC
Until now, we have covered the standard aspects of AI and machine learning development. We're now entering the territory of data versioning and model tracking. This is where the real magic of efficient AI development comes into play, transforming how we manage and evolve our machine-learning projects.
- Better Operations: Data versioning and model tracking are crucial for AI project management.
- Data Versioning: Efficiently manage data changes and maintain historical accuracy for model consistency and reproducibility.
- Model Tracking: Start tracking model iterations, identify improvements, and ensure progressive development.
Streamlining Workflow with DVC Commands
To effectively integrate Data Version Control (DVC) into your workflow, we break down the process into distinct steps, ensuring a smooth and understandable approach to data and model versioning.
Initializing DVC
Start by setting up DVC in your project directory. This initialization lays the groundwork for subsequent data versioning and tracking.
dvc init
Setting Up Remote Storage
Configure remote storage for DVC. This storage will host your versioned data and models, ensuring they are safely stored and accessible.
dvc remote add -d myremote /tmp/myremote
Versioning Data with DVC
Add your project data to DVC. This step versions your data, enabling you to track changes and revert if necessary.
dvc add data
Versioning Models with DVC
Similarly, add your ML models to DVC. This ensures your models are also versioned and changes are tracked.
dvc add model
Committing Changes to Git
After adding data and models to DVC, commit these changes to Git. This step links your DVC versioning with Git's version control system.
git add data.dvc model.dvc .gitignore
git commit -m "Add data and model"
Pushing to Remote Storage
Finally, push your versioned data and models to the configured remote storage. This secures your data and makes it accessible for collaboration or backup purposes.
dvc push
Tagging a Version
Create a tag in Git for the current version of your data:
git tag -a v1.0 -m "Version 1.0 of data"
Updating and Versioning Data
- Make Changes to Your Data:
-Modify your data.csv as needed. - Track Changes with DVC:
-Run dvc add again to track changes:
dvc add data
- Commit the New Version to Git:
- -Commit the updated DVC file to Git:
git add data.dvc
git commit -m "Update data to version 2.0"
- Tag the New Version:
- -Create a new tag for the updated version:
git tag -a v2.0 -m "Version 2.0 of data"
Switching Between Versions
- Checkout a Previous Version:
- -To revert to a previous version of your data, use Git to checkout the corresponding tag:
git checkout v1.0
- Revert Data with DVC:
- -After checking out the tag in Git, use DVC to revert the data:
dvc checkout
Understanding Data Tracking with DVC
DVC offers a sophisticated approach to data management by tracking pointers and hashes to data rather than the data itself. This methodology is particularly significant in the context of Git, a system not designed to efficiently handle large files or binary data.
How DVC Tracks Data
- Storing Pointers in Git:
-DVC stores small .dvc files in Git. These pointers reference the actual data files.
-Each pointer contains metadata about the data file, including a hash value uniquely identifying the data version.
- Hash Values for Data Integrity:
-DVC generates a unique hash for each data file version. This hash ensures the integrity and consistency of the data version being tracked.
-Any change in the data results in a new hash, making it easy to detect modifications.
- Separating Data from Code:
-Unlike Git, which tracks and stores every version of each file, DVC keeps the actual data separately in remote storage (like S3, GCS, or a local file system).
-This separation of data and code prevents bloating the Git repository with large data files.
Importance in the Context of Git
- Efficiency with Large Data:
-Git struggles with large files, leading to slow performance and repository bloat. DVC circumvents this by offloading data storage.
-Developers can use Git as intended – for source code – while DVC manages the data.
- Enhanced Version Control:
-DVC extends Git's version control capabilities to large data files without taxing Git's infrastructure.
-Teams can track changes in data with the same granularity and simplicity as they track changes in source code.
- Collaboration and Reproducibility:
-DVC facilitates collaboration by allowing team members to share data easily and reliably through remote storage.
-Reproducibility is enhanced as DVC ensures the correct alignment of data and code versions, which is crucial in data science and machine learning projects.
Using DVC as a Feature Store
DVC can be a feature store in machine learning workflows. It offers advantages such as version control, reproducibility, and collaboration, streamlining the management of features across multiple projects.
What is a Feature Store?
A feature store is a centralized repository for storing and managing features - reusable pieces of logic that transform raw data into formats suitable for machine learning models. The core benefits of a feature store include:
- Consistency: Ensures uniform feature calculation across different models and projects.
- Efficiency: Reduces redundant computation by reusing features.
- Collaboration: Facilitates sharing and discovering features among data science teams.
- Quality and Compliance: Maintains a single source of truth for features, enhancing data quality and aiding in compliance with data regulations.
Benefits of DVC in Feature Management
- Version Control for Features: DVC enables version control for features, allowing tracking of feature evolution.
- Reproducibility: Ensures each model training is traceable to the exact feature set used.
- Collaboration: Facilitates feature-sharing across teams, ensuring consistency and reducing redundancy.
Setting Up DVC as a Feature Store
- Organizing Feature Data: Store feature data in structured directories within your project repository.
- Tracking Features with DVC: Use DVC to add and track feature files (e.g., dvc add data/features.csv).
- Committing Feature Changes: Commit changes to Git alongside .dvc files to maintain feature evolution history.
Using DVC for Feature Updates and Rollbacks
- Updating Features: Track changes by rerunning dvc add on updated features.
- Rollbacks: Use dvc checkout to revert to specific feature versions.
Best Practices for Using DVC as a Feature Store
- Regular Updates: Keep the feature store up-to-date with regular commits.
- Documentation: Document each feature set, detailing source, transformation, and usage.
- Integration with CI/CD Pipelines: Automate feature testing and model deployment using CI/CD pipelines integrated with DVC.
Implementing a DVC-Based Feature Store Across Multiple Projects
- Centralized Data Storage: Choose shared storage that is accessible by all projects and configure it as a DVC remote.
- Versioning and Sharing Features: Version control feature datasets in DVC and push them to centralized storage. Share .dvc files across projects.
- Pulling Features in Different Projects: Clone repositories and pull specific feature files using DVC, enabling their integration into various workflows.
Best Practices for Managing a DVC-Based Feature Store Across Projects
- Documentation: Maintain comprehensive documentation for each feature.
- Access Control: Implement mechanisms to regulate access to sensitive features.
- Versioning Strategy: Develop a clear strategy for feature versioning.
- Automate Updates: Utilize CI/CD pipelines for updating and validating features.
Streamlining ML Workflows with CML IntegrationIntegrating Continuous Machine Learning (CML) is a game-changer for CI/CD in machine learning. It automates critical processes and ensures a more streamlined and efficient workflow.Setting Up CML WorkflowsCreate a GH Actions workflow within your GitHub repository, ensuring it is configured to run on every push or PR.name: model-training
on: [push]
jobs:
run:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install Poetry
run: pipx install poetry
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: "3.10"
cache: "poetry"
- name: Install dependencies
run: poetry install --no-root
- uses: iterative/setup-cml@v2
- name: Train model
run: |
make run
- name: Create CML report
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
echo "\`\`\`" > report.md
cat report.txt >> report.md
echo "\`\`\`" >> report.md
echo "" >> report.md
cml comment create report.md
Conclusion: Boosting Software and AI Ops
In wrapping up, we've delved into the core of DataOps and MLOps, demonstrating their vital role in modern software development, especially in AI. By mastering these practices and tools like DVC and CML, you're learning new techniques and boosting your skillset as a software developer.
- Stay Agile and Scalable: Adopting DataOps and MLOps is essential for developing in the fast-paced world of AI and keeping your projects agile and scalable.
- Leverage Powerful Tools: Mastery of DVC and CML enables you to manage data and models efficiently, making you a more competent and versatile developer.
- Continuous Learning and Application: The journey doesn’t end here. The true potential is realized in continuously applying and refining these practices in your projects.
This is more than just process improvement; it's about enhancing your development workflows to meet the evolving demands of AI and software engineering.
Elevating engagement in hybrid workspaces

Last August, Zoom (famous for helping us connect during the pandemic), ironically recalled their workforce to the office. You’ve likely noticed this trend of companies bringing their teams back to IRL too. I know that, in my network, people are being urged to return to on site work 2-3 times per week.
While I support the argument for boosting engagement and collaboration, I can’t quite understand the decision to impose a set amount of days per week. I anticipate that workers who thrive in remote work environments might become less engaged, or just leave. And will the problem of lower engagement magically be solved, just by having people back in the same physical location? I doubt it. After all, disengagement and lack of cohesion in teams existed pre-pandemic. Perhaps a collective pause is required to bring more creative solutions to the forefront.
In our recent focus groups at Osedea, our team has been clear: they wish their colleagues would be there more in person… but on the flip side of the coin, unilaterally, everyone appreciates the extreme flexibility we offer.
In this piece, I share my reflections and our learnings about shifting work dynamics in hopes that it may help you in your own reflections.
Create memorable moments together
Gregg Popovich, legendary head coach of the San Antonio Spurs takes his team after every game to a great culinary experience. Now, NBA players (many of them millionaires), can certainly afford their own dinner. But, as quoted by former Spurs guard Danny Green in a 2020 ESPN article about Popovich mindset, “dinners help us have a better understanding of each individual person, which brings us closer to each other…and, on the court, understand each other better.”
Indeed, nothing spells team bonding like living memorable and unique experiences together. This is something we were really good at in Osedea’s early days when our team was smaller. Each year, we planned a five-day all-inclusive vacation with our team. The goal was to receive training and bond—boosting engagement and collaboration. You can read more about our 2018 trip to Lisbon here.
As we grew in size, the logistics of arranging regular team trips became more challenging. So this year, we channeled the mindset of our team trips, and applied it to the launch of OsedeaFest: two action-packed days of inspiring training sessions, delicious dining, and exploring our city. The result? A spike in team engagement and connection, as per our results in Officevibe and our team’s feedback.
Organize your in-person days around rituals
There are certain activities that make more sense in person, while others don't. For instance, last summer we resumed in-person interviews. It gives us a chance to connect and make the candidate experience more memorable. Similarly, client demos are a great opportunity to develop rapport and offer a positive collaborative experience. Now, whenever we organize certain types of rituals we ask ourselves: is this better in person, remote, or does either work fine? We now organize our in-person days around this, instead of just assigning an arbitrary number of days people are required to be physically present.
Provide flexibility. Get flexibility in return.
Our team reports loving the flexibility we offer. Some team members like me (thank you, four-minute commute!) come to the office most days. Others are regulars, but without set days. Others still are rarely there in person. However, when we have a day of interviews, we never have to beg our team to show up or negotiate their presence. We know that they respect the process, even if they’re the type of person who prefers remote work.
Communicate differently to engage your teams effectively
One comment that I hear a lot from other company leaders is that they worry that if they go fully remote, their team will be disengaged with their company. If you think being there in person for communication will prevent you from having a disengaged workforce, I invite you to think again. We have to challenge ourselves as leaders to think differently and find innovative ways to communicate and engage the team.
Here are some things we’ve done to enhance communication and engagement:
- Engage your audience by exploring meaningful mediums. Our daily team newsletter ran for three years before it started to lose impact. We shifted gears to a highly engaging medium: an internal podcast. Once a week, we broadcast an episode showcasing different team members. It’s a great way to create a personal connection with audience members and the team can listen whenever it’s convenient for them.
- Revamp existing communication rituals. We had been running our quarterly update the same way (in traditional video conference style with slides and various presenters) since our inception. To make the presentation of this important content more dynamic, we switched things up this fall with a virtual talk show style format.
Final words
According to Indeed, hybrid work is here to stay with more than 42% of posted jobs across industries including hybrid in their offering. But hybrid work can be so much more inspiring and rewarding for your team than a monotonous rule of a set number of days per week at the office. Flexibility and a tailored-to-your-team approach may be stronger differentiators to attract talent and offer rich professional experiences. So, before hopping on the return-to-the-office wagon, I urge you to ask yourself, “can we do better?”
How we run the show at OSEDEA (without any bosses)
At Osedea, we have a very unique organizational structure. We’re inspired by humanocracy, an approach coined by Gary Hamel —a researcher at Harvard University. His data-driven argument is about making efforts to bypass bureaucracy, forgo managers, and shift an organization’s DNA to give team members an equal chance to learn, grow, and contribute.
This is a new experience for many people in the workplace, so we wanted to share our thoughts and answer any questions you might have about joining a company like ours that operates with this kind of structure.
First things first, what is a bureaucracy?
Bureaucracies originated in the 18th century. They were designed around position and individuals to address nepotism (assigning positions of power by way of favouritism to friends and family members). Bureaucracy was also designed to have rules, practices, and principles to maximize compliance of a group of people. Later in the 20th century, sociologist Max Weber remarked that, “bureaucracy is more perfect when it’s more dehumanizing.”
You’ve likely worked in a bureaucracy, as the vast majority of organizations are structured this way:
- There’s a formal hierarchy (a top-down approach and many levels)
- Power is vested in positions (people with certain roles have more power than others)
- Managers assign tasks and assess performance
- Everyone competes for promotions and compensation correlates with rank
Gary Hamel’s research showed some concerning data about bureaucracies:
- 79% of people polled said bureaucracy significantly slows decision-making
- 68% said, in their organization, new ideas are met with skepticism or outright resistance
- 76% said political behaviours highly influence who gets ahead, not competence or potential
Maybe you've even been frustrated in a traditional hierarchical environment? Here’s why organizations stick with it:
- They’re a familiar way to organize humans into action
- It’s hard to imagine alternatives
- They work to a certain extent; things get done, we’re able to control/coordinate, and to have consistency
- As bureaucracies have been around since the 18th century, millions of careers have been built around the desire to climb corporate ladders and attain positions of power; we’re reluctant to change as humans
Letting go of the familiarity of bureaucracy requires courage, creativity and a desire for a more humane organization. As a society we can work towards this.
From bureaucracy to humanocracy
Osedea was structured around the individuals within our organization, as opposed to a corporate structure. In our opinion, bureaucracies can be dehumanizing. They can encourage bad behaviour in people, power plays, and politics. Those who get ahead aren’t necessarily rewarded for behaviours that are helpful to the organization. Senior management tends to reward people who prioritize their self-interests, those who excel at “managing up,” and people who are good at reading management moods/meeting their manager’s needs (as opposed to the organization’s needs).
At Osedea, we decided on a “structure without managers.” This is a bit different than a “flat structure,” which is a widely-, but oftentimes incorrectly-, used term to describe a structure with only a few layers of management and a short chain of command, that can hardly survive growth and appears to be the dream but ends up being a logistical nightmare and chaos. Interested about learning more, here are you a few things that you might not know about a flat structure.
Why we chose a structure without managers
- This type of structure is in line with our vision of creating a world of opportunities for our team while making their work life enjoyable.
- It boosts creativity, learning and autonomy.
- It fosters “horizontal” instead of “vertical” ambition. "Vertical" ambition is the usual career-path trajectory, in which a newbie moves up the ladder from associate to manager to vice president over a number of years of service. "Horizontal" ambition is where employees who love what they do are encouraged to dig deeper, expand their knowledge, and become better at it. This doesn’t mean horizontal has no evolution. Instead of rewarding high performers with managerial responsibilities—which often drives people further away from the job they are actually good at—we reward them with responsibilities closer to the work. We complement that with values, benefits and autonomy.
- People can make contributions at Osedea no matter what their experience level is.
- It drives results faster.
- It removes the negative impacts of bureaucracy.
This is not to say that everything in our structure works perfectly—we have to remember that organizations are always a work in progress. We have a destination but there will be challenges. Some will be easy to fix, some will stick around, and new challenges will pop up. It’s sometimes hard to imagine how an institution could function without a formal organization, but we should try.
Some common misconceptions about our structure
Without managers there are no leaders.
It’s important to understand that a manager isn’t necessarily a leader. At Osedea we don’t believe in assigned leadership, we believe in leadership that is built through high quality work, curiosity in building towards our company vision and natural influence with others. There’s always a “lead” on each project or initiative team—someone who is responsible for holding everyone accountable to the delivery of the project and who is the go-to. But, we don’t believe in a structure where there’s a person who is a boss of devs, a person who is the boss of designers, a person who is a boss of sales, etc.
Without managers there is chaos and decisions are impossible to make.
We organize everything through efficient processes, team expectations and natural leadership. You might think that without a boss who is the final decision maker, we can’t move forward, or that everyone gets a say in every decision. People who have ownership over a specific project and full understanding and information of context should contribute. But in the end, someone makes a decision based on information, input and what’s best for our company vision, values, stakeholders and business needs.
Without a manager I can’t have a career progression and there is no mentorship, coaching, or feedback.
We believe in a career of achievements and that there are several paths that lead to success, not only the management path. And even though we don’t have managers, we have processes and metrics in place to ensure that our people grow to their full potential and get proper feedback, that performance is evaluated, and team members get coaching.
Because I can’t get promoted, there are no incentives for me to perform and contribute.
At Osedea, strong performance is rewarded financially and with additional growth opportunities (e.g. when we send our developers to speak at international conferences, even if they aren’t the most senior in our company, or how our full stack developer was given a chance to work 1:1 with Spot the robot). We’re agile, we think outside the box, we reward paths that aren’t on a traditional career ladder, and we ask team members to contribute where they’re strongest and reap the most enjoyment.
Your current structure is fine now that you’re under 100 employees, but there’s no way you can maintain it as you grow.
Growth is key for every company, but not for us if it risks bringing down our humanocracy approach. Can a structure like ours survive long term: YES! Does it mean there won’t be adjustments and improvements? NO. We have to constantly work on it. We stick to our vision, but it doesn’t mean our day-to-day will always be the same.
Today, we have offices in Montréal, Canada and Nantes, France, with another opening soon in the UK. Our international offices are independent but united around the same mission, values and strategies. This way we can ensure that, as we scale up, we maintain our humane approach.
Streamlining Predictive Analytics with Scikit-Learn
Predictive analytics empowers organizations to forecast future events by leveraging past data. When diving into this work, especially from a Minimum Viable Product (MVP) perspective, a streamlined yet robust tool is essential, and I love getting started with Scikit-Learn. It’s my initial playground for predictive analytics exploration.
Overview of Predictive Analytics
In a recent workshop - "Identifying Opportunities to Leverage AI Within the Manufacturing Sector", we explored the ability of AI to transform the manufacturing domain. Though the discussion primarily focused on manufacturing, the insights are applicable across many sectors.
At its core, predictive analytics is a domain-agnostic tool that is helpful across all domains, from healthcare to finance to retail and beyond.
The essence of predictive analytics lies in using historical data coupled with AI and machine learning to predict future outcomes. This foresight facilitates strategic decision-making, minimizes risks, and reduces downtime costs by flagging potential blockers and issues. This lets us optimize operations and maximize profits.
Some example applications:
- Manufacturing: Employing predictive maintenance to reduce machinery downtime.
- Healthcare: Augmenting early diagnosis and risk evaluation of diseases.
- FinTech: Strengthening fraud detection and credit risk assessment.
One bonus of predictive analytics lies in its transferability; we can borrow strategies from one domain to bring innovation to another.
From Problem to MVP Deployment
Transitioning from a problem statement to an MVP includes:
- Problem outline to actionable insights.
- Acquisition, cleaning, transformation, and structuring of data.
- Model building and validation.
- Fine-tuning models to align with the context.
I believe in people, process, and product forming the foundation of technical innovation. We can build great solutions by always starting with a question and a thorough understanding of the context, user narratives, and stakeholders.
Scikit-Learn: The MVP
While numerous tools and platforms are available for predictive analytics, Scikit-Learn stands out for its simplicity, ease of use, and efficiency, making it my preferred choice for MVPs and proof-of-concept projects. It’s a library that lowers the entry barrier, making the initial step into predictive modelling less daunting and more structured.
The benefit of Scikit-Learn lies in its gentle learning curve, which is helpful for individuals with a foundational understanding of Python. It has a well-organized, consistent, and intuitive API that accelerates onboarding. Furthermore, it has a rich library of algorithms for various machine learning tasks, providing a robust platform to build, experiment, and iterate on predictive models. The modular design promotes extensibility and interoperability with other libraries, enhancing its appeal for MVP development. The simple yet powerful nature of Scikit-Learn makes it an excellent choice for rapid prototyping, accelerating the process from concept to a working model, ready for real-world validation.
Problem Dimensions
Predictive analytics typically revolves around classification (categorizing data) or regression (forecasting continuous values):
- Classification: Categorizing data when the outcome variable belongs to a predefined set (e.g., 'Yes' or 'No').
- Regression: Forecasting continuous values when the outcome variable is real or continuous (e.g., weight or price).
Practical Example: Diabetes Progression Analysis
Let’s illustrate this with a practical example using a healthcare dataset on diabetes progression. Thanks to Scikit-Learn, accessing a toy diabetes dataset is simple. This dataset contains ten variables like age, BMI, and blood serum measurements for over 400 diabetes patients.
We’re looking to answer the following user stories:
- Healthcare Executive: Streamlining patient intake for timely intervention.
- Doctor: Identifying factors contributing to accurate diabetes progression prediction.
- Patient: Utilizing health metrics to understand and potentially mitigate diabetes progression risks.
import pandas as pdfrom sklearn import datasets# Load the diabetes datasetdiabetes = datasets.load_diabetes()data = pd.DataFrame(data=diabetes.data, columns=diabetes.feature_names)data["target"] = diabetes.target
Preliminary Analysis and Model Building
Before diving into model building, conducting an exploratory analysis is crucial. It often unveils insights that drive the choice of predictive models and features.
import matplotlib.pyplot as pltimport seaborn as sns# Display the first few rows of the datasetdata.head()# Summary statisticsdata.describe()# Correlation matrixplt.figure(figsize=(10, 8))sns.heatmap(data.corr(), annot=True)plt.show()

The correlation matrix displays the relationships between various features and the target variable in the diabetes dataset. Here are the key insights from the correlation matrix:
BMI and Target Correlation:
- There's a positive correlation between BMI (Body Mass Index) and the target variable, suggesting that as BMI increases, the diabetes measure also tends to increase.
Blood Pressure (bp) and Target Correlation:
- Blood pressure shows a positive correlation with the target variable. This indicates that higher blood pressure values are associated with higher diabetes measures.
Negative Correlation of S3 and Target:
- S3 exhibits a negative correlation with the target variable, indicating that higher values of S3 are associated with lower values of the diabetes measure.
Correlation Among Features:
- The features S1 and S2 show a high positive correlation, indicating a strong linear relationship between them.
- S4 and S3 have a strong negative correlation, showing that as one variable increases, the other tends to decrease significantly.
- The S4 and S2 and S4 and S5 pairs also exhibit strong positive correlations, suggesting that these features are likely moving together.
Age Correlation:
- Age has a positive correlation with various features, including blood pressure (bp), S5, and S6, and a lesser but still significant positive correlation with the target variable.
Data Preprocessing
Data Preprocessing is vital in building a machine learning model as it prepares the raw data to be fed into the model, ensuring better performance and more accurate predictions. In this process, standardizing the data and splitting it into training and testing sets are essential steps.
The first objective here is to have separate datasets for training and evaluating the model. A common rule of thumb is the 80-20 rule, where 80% of the data is used for training and the remaining 20% for testing. This ratio provides a good balance, ensuring that the model has enough data to learn from while still having a substantial amount of unseen data for evaluation.
Second, standardization is crucial for many machine learning algorithms, especially distance-based and gradient descent-based algorithms. It scales the data to have a mean of 0 and a standard deviation of 1, thus ensuring that all features contribute equally to the computation of distances or gradients.
from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler# Splitting the data into training and testing setsX = data.drop("target", axis=1)y = data["target"]X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42)# Standardize the datascaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
Model Building - Linear Regression
Linear Regression is a simple first step in predictive analytics due to its straightforwardness and ease of interpretation. It operates under supervised learning, establishing a linear relationship between the input features and the target variable.
from sklearn.linear_model import LinearRegression# Create and train the modellr = LinearRegression()lr.fit(X_train, y_train)
The simplicity of Linear Regression lies in both its single-line training command and its model output, which is easy to interpret. The coefficients tell us the weight or importance of each feature, while the intercept gives us a baseline prediction when all feature values are zero. This interpretability makes Linear Regression an excellent starting point for model building and a valuable tool for communicating findings to stakeholders.
Evaluating and Visualizing Outcomes
Evaluating a model's performance lies in understanding its accuracy and identifying areas of improvement. One standard metric used in regression tasks is the Mean Squared Error (MSE), which quantifies the average squared difference between actual and predicted values. A lower MSE value indicates a better fit of the model to the data, although it's important to note that MSE is sensitive to outliers.
Visualizing the relationship between actual and predicted values further illuminates the model's performance. A scatter plot is a handy tool for this purpose, clearly representing how well our model's predictions align with the actual values. The closer the points cluster around the line of identity (a line with a slope of 1, passing through the origin), the better our model makes accurate predictions.
from sklearn.metrics import mean_squared_errorimport numpy as np# Predictionsy_pred = lr.predict(X_test)# Calculating and displaying the Mean Squared Errormse = mean_squared_error(y_test, y_pred)print(f"Mean Squared Error: {mse}")# Visualizing the actual values and predicted valuesplt.scatter( y_test, y_pred, alpha=0.5) # Added alpha for better visualization if points overlapplt.xlabel("Actual values")plt.ylabel("Predicted values")plt.title("Actual values vs Predicted values")# Adding line of identitylims = [ np.min([plt.xlim(), plt.ylim()]), # min of both axes np.max([plt.xlim(), plt.ylim()]),] # max of both axes# now plot both limits against each otherplt.plot(lims, lims, color="red", linestyle="--")plt.xlim(lims)plt.ylim(lims)plt.show()

In this visualization, the red dashed line represents the line of identity, where a perfect model would have all points lie. Deviations from this line indicate prediction errors. Such a visual aid provides a qualitative insight into the model's performance. It serves as a tangible explanation tool for stakeholders, showcasing the model's strengths and areas needing enhancement in a digestible format.
Transitioning to a Classification Problem
Our first approach used a linear regression model to predict the continuous target variable representing diabetes progression. However, as evaluated by the Mean Squared Error, the model's performance has room for improvement.
Transforming the problem into a binary classification scenario often brings a different perspective and could lead to better performance. In some instances, by changing it into a binary classification problem, we aim to predict whether a patient's diabetes has progressed based on a predetermined threshold.
Let's define progression as a binary variable: `1` if the progression measure is above a certain threshold and `0` otherwise. We'll choose the median of the target variable in the training set as the threshold for simplicity:
pythonfrom sklearn.preprocessing import Binarizer# Defining the thresholdthreshold = np.median(y_train)# Transforming the target variablebinarizer = Binarizer(threshold=threshold)y_train_class = binarizer.transform(y_train.values.reshape(-1, 1))y_test_class = binarizer.transform(y_test.values.reshape(-1, 1))
We can proceed with a classification model now that we have our binary target variable. A common choice for such problems is Logistic Regression:
from sklearn.linear_model import LogisticRegression# Training the Logistic Regression modellr_class = LogisticRegression()lr_class.fit(X_train, y_train_class.ravel())# Making predictions on the test sety_pred_class = lr_class.predict(X_test)
Evaluate the Model
After training, evaluating the model on unseen data is essential to gauge its performance and robustness. Scikit-Learn provides various tools, including a classification report and a confusion matrix, which are used for classification problems. Through these metrics, we can understand the model's accuracy, misclassification rate, and other crucial performance indicators.
Classification Report
The classification report provides the following key metrics for each class and their averages:
- Precision: The ratio of correctly predicted positive observations to the total predicted positives. High precision relates to the low false positive rate.
- Recall (Sensitivity): The ratio of correctly predicted positive observations to the total observations in the actual class. It tells us what proportion of the actual positive class was identified correctly.
- F1-Score: The weighted average of Precision and Recall.
- Support: The number of actual occurrences of the class in the specified dataset.
from sklearn.metrics import classification_report# Evaluating the modelclass_report = classification_report(y_test_class, y_pred_class)print(class_report)
precision recall f1-score support 0.0 0.77 0.82 0.79 49 1.0 0.76 0.70 0.73 40 accuracy 0.76 89 macro avg 0.76 0.76 0.76 89weighted avg 0.76 0.76 0.76 89
Confusion Matrix
A Confusion Matrix is a table used to evaluate a classification model's performance. It not only gives insight into the errors made by a classifier but also the types of errors being made.
from sklearn.metrics import ConfusionMatrixDisplaydisp = ConfusionMatrixDisplay.from_estimator( lr_class, X_test, y_test_class, display_labels=["Not Progressed", "Progressed"], cmap=plt.cm.Blues,)plt.show()

In this visualization, each matrix column represents the instances in a predicted class, while each row represents the instances in an actual class. The label “Not Progressed” is mapped to 0, and “Progressed” is mapped to 1. The diagonal elements represent the number of points for which the predicted label is equal to the true label, while off-diagonal elements are those that the model misclassifies.
This colour-coded matrix represents the classifier's performance, where darker shades represent higher values. Hence, the diagonal would be distinctly darker for a well-performing model than the rest of the matrix.
Dimensionality Reduction and Visualization
In Predictive Analytics, our models often work with many dimensions, each representing a different data feature. However, navigating through high-dimensional space is tricky and not intuitive. This is where dimensionality reduction techniques like t-SNE (t-Distributed Stochastic Neighbor Embedding) come into play, acting as a bridge from the high-dimensional to a visual, often 2-dimensional, representation.
Visualizing high-dimensional data in a lower-dimensional space, like 2D, helps understand the data distribution and the model's decision boundaries.
from sklearn.manifold import TSNE# Create a TSNE instancetsne = TSNE(n_components=2, random_state=42)# Fit and transform the datatransformed_data = tsne.fit_transform(X_test)# Visualizing the 2D projection with color-codingplt.scatter( transformed_data[:, 0], transformed_data[:, 1], c=np.squeeze(y_test_class), cmap="viridis", alpha=0.7,)plt.xlabel("Dimension 1")plt.ylabel("Dimension 2")plt.title("2D TSNE")plt.colorbar(label="Progressed (1) vs Not Progressed (0)")plt.show()

The colour-coded scatter plot produced in the code above shows how the diabetes progression (categorized as Progressed and Not Progressed) is distributed across two dimensions. Each point represents a patient, and the colour indicates the progression status. This visual can reveal clusters of similar data points, outliers, or patterns that might correlate with the predictive model's performance.
This 2D visualization might unveil hidden relations between features and the target variable or among the features themselves. Such insights can guide further feature engineering, model selection, or hyperparameter tuning to enhance the model's predictive power potentially.
Such visualizations can also be a powerful communication tool when discussing the model and the data with non-technical stakeholders. It encapsulates complex, high-dimensional relationships into a simple, interpretable form, making the conversation around the model's decisions more accessible.
Recap
This walkthrough demonstrates how to quickly move from a real-world problem to a simple MVP using Scikit-Learn for predictive analytics. The journey from understanding the problem, preprocessing the data, building, and evaluating the models, to finally visualizing the outcomes is filled with learning at every step. With simple but powerful tools like Scikit-Learn, predictive analytics is accessible for all stakeholders.
Spot Meets Canadian Prime Minister Justin Trudeau at ALL IN
We had the opportunity to participate in the ALL IN event on September 27 and 28, 2023, the largest gathering dedicated to AI in Canada. Innovation is at the heart of the Canadian economy and our values at Osedea, and we were inspired by the innovative ideas of the companies present at this event.

Our famous robot, Spot, had the honor of meeting the Prime Minister of Canada, Justin Trudeau, who even had the opportunity to pilot it. Service robots, such as Boston Dynamics' Spot robot, contribute to automating repetitive and low-value tasks for humans, which is a significant asset to the Canadian economy. They will enable businesses to overcome challenges related to labor shortages, increase their efficiency, and enhance their competitiveness in global markets.



We also had the opportunity to present the Spot robot during a 20-minute conference with Thierry Marcoux and Armand Brière. The goal was to popularize service robots and explain concretely the utility of the Spot robot.

We would like to thank Isabelle Turcotte, Patrick Ménard, Louis Deslauriers, M.Sc. , Charlotte BA and the entire ALL IN team for this wonderful opportunity. You have done an incredible job in organizing a world-class AI event.
Capitalizing on your organization’s data with vector databases
At Osedea, we’re constantly at the forefront of emerging technologies, and we have a unique perspective on tech adoption trends among our diverse client base. In recent months, AI has made its way into mainstream media with the help of ChatGPT. Since then, tooling and support for AI development have skyrocketed. Just a few weeks ago, Dr. Andrew Ng, a globally recognized leader in AI, delivered a talk on the opportunities in AI which highlighted the importance of integrating AI into your organization's workflow.
BEARING.ai—the first company to harness the power of Generative AI in the maritime shipping industry—is a great example of how AI adoption can quickly reap tremendous benefits. Leveraging their data to monitor, forecast, simulate, and optimize, BEARING.ai’s clients have achieved substantial improvements in shipping vessel performance while simultaneously reducing fuel costs and carbon emissions, contributing to a greener environment. Similar opportunities aren't distant dreams; they’re within grasp. AI is ripe for adoption, and the key to unlocking its full potential lies in harnessing your organization's data.
The benefits of centralizing data
For many established companies, data has been accumulating for years across various departments and systems. PDFs, images, presentations, emails, audio, video, and analytics are treasure troves of information (and significant assets when harnessed correctly). The first step towards adopting AI within your organization is centralizing your data. Centralization (consolidating from various sources/locations into a single repository or system) by implementing a unified data management platform or integrating existing systems through middleware solutions offers numerous benefits:
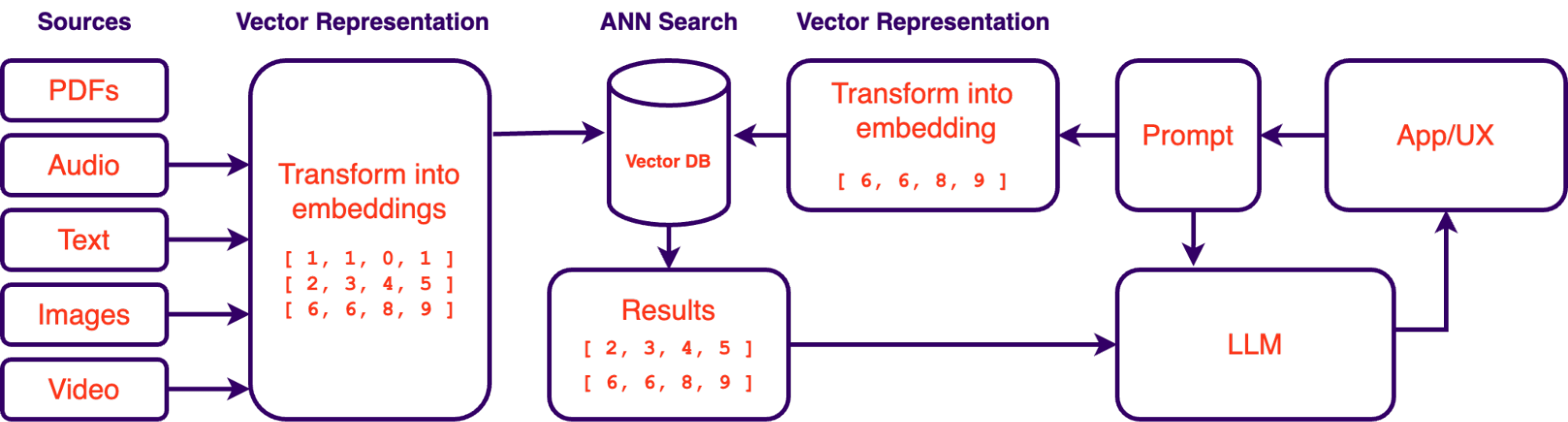
AI-Powered Knowledgebase: Once centralized, data can be organized and indexed efficiently with the help of embedding models. These models are trained to extract the most meaningful information out of your unstructured data. By indexing your data in this manner, Large Language Models such as GPT-4 can have their context extended with your organization's business context to evolve into a comprehensive, all-knowing assistant. This innovative approach is known as retrieval augmented generation (RAG) with vector databases, a concept we will delve into shortly.
Training Predictive Models: The consolidated data pool becomes a valuable resource for training AI models. Predictive analytics, forecasting, and trend analysis become achievable goals as you capitalize on your organization's historical data.
Security Benefits: Centralizing data provides a more robust security infrastructure to safeguard sensitive information. It allows for more effective access control and auditing, reducing the risk of data breaches.
Easier Backups: Centralized data is easier to back up than data from multiple disparate sources. This simplifies data protection measures, ensuring critical information is securely preserved and recoverable in case of data loss incidents.
Redundancy: Implementing redundancy, such as data mirroring or replication, becomes more feasible with centralized data. Redundancy enhances data availability and fault tolerance, minimizing downtime, and ensuring business continuity.
Building an AI-powered knowledgebase
As mentioned above, retrieval augmented generation systems (RAG) have gained prominence as a valuable solution for querying an organization's data using large language models (LLMs). RAG systems allow for querying data with natural language. Essentially, it gives you a way of “talking” to your data in the same way you talk to ChatGPT. The accessibility of LLMs in recent months has made this approach a lot more feasible which is why this approach to data exploration is quickly gaining traction. However, the success of such systems depends not only on LLMs and prompt engineering but also on the proper vectorization and indexing of data. This is where vector databases and embeddings play a crucial role.
What are Vector Embeddings?
In the context of AI and machine learning, vector embeddings are a numeric representation of an entity's semantics. These representations capture essential features and relationships within the data, making it easier for AI algorithms to process and understand. Embeddings are crucial for tasks such as natural language processing, recommendation systems, and image recognition. With embeddings, we can quickly find related content based on similarity. Additionally, embeddings aren’t just limited to text, it’s possible to create vectors out of images, audio, video, or any type of data using encoder models that have been trained to extract their meaningful information. Some models like OpenAIs text-embedding-ada-002 are even language agnostic, meaning that they can understand similarity in various languages natively.
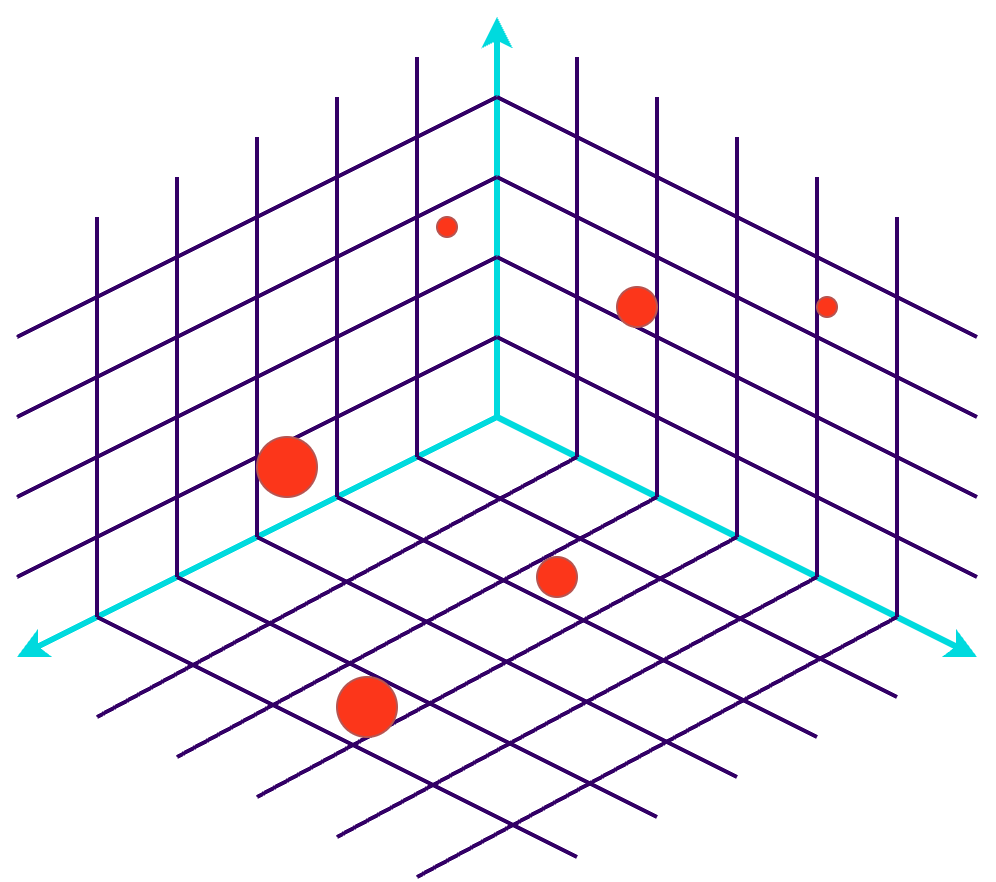
What are vector databases?
A vector database is a specialized database designed to store and retrieve high-dimensional vector embeddings efficiently, making them ideal for AI and machine learning applications. They use approximate nearest neighbor (ANN) search algorithms to measure the distance between embeddings, resulting in a ranked list of neighboring vectors.
As an example, Spotify has been using vector databases for quite some time to compare users' taste in music, they also go into detail on how they’ve used embeddings to query their podcast episodes in their blog post: Introducing Natural Language Search for Podcast Episodes. They’ve even gone as far as creating their own ANN library!
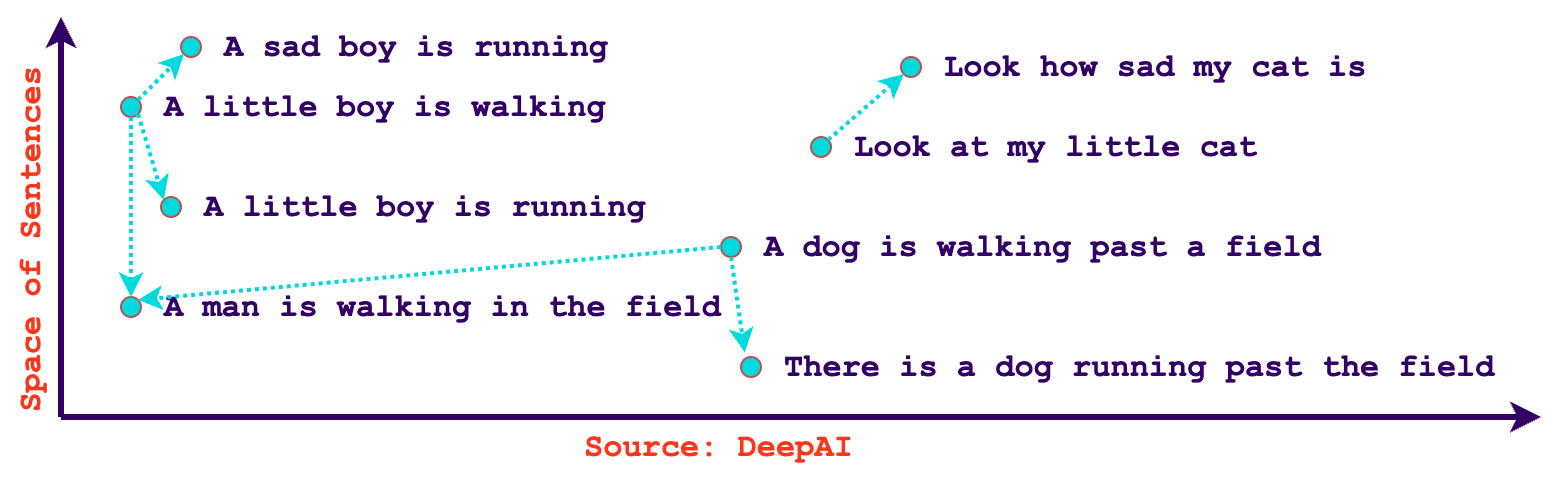
Use cases for vector databases
Vector databases are well-suited for a wide range of use cases that involve similarity search, recommendation systems, and data analysis in fields such as machine learning, natural language processing, computer vision, and more. Here are some common use cases for vector databases:
Recommendation Systems: Vector databases are often used in recommendation systems to find items or content that are similar to what a user has interacted with in the past. This can be applied to e-commerce, content recommendation, and music or video streaming platforms.
Content-Based Search: In multimedia content platforms, vector databases enable content-based search for images, audio, and video files. Users can search for content with similar visual or auditory features.
Anomaly Detection: Detecting anomalies in high-dimensional data, such as network traffic logs, sensor data, or financial transactions, can be done using vector databases. Unusual data points can be identified by comparing them to a set of normal vectors.
Collaborative Filtering: Collaborative filtering algorithms can use vector databases to find users with similar preferences and recommend items based on the behaviour of similar users.
Long-term Memory: Vector databases can be used to store past response generations for an LLM. These embeddings can be recalled to further enhance a large language model’s context with its past context.
Clustering: In vector databases, clustering can be applied to organize data into distinct groups, making it easier to identify patterns and similarities within the dataset.
Diversity Measurement: In vector databases, diversity measurement can be applied to evaluate the breadth and inclusivity of recommendations, ensuring a balanced selection of items or content to cater to a wide range of user preferences or topics.
Pitfalls of embedding models and vector databases
While embeddings are powerful, they are not without their challenges. It's important to be aware of potential pitfalls, such as bias in the training data. As an example, OpenAI explains in their documentation how they’ve witnessed a model more strongly associate European American names with positive sentiment when compared to African American names. Additionally, embedding models have cutoff dates on their training data, meaning some data might differ in semantics throughout time (e.g. a celebrity’s popularity). Selecting the right embedding techniques and parameters is critical to achieving optimal results and correct data pre-processing techniques need to be applied to correctly leverage embeddings.
Vector databases are only half the solution
While vector databases and embeddings are essential components of AI adoption, it's crucial to recognize that they’re part of a more extensive ecosystem. Building a robust AI infrastructure involves addressing other key aspects, such as data preprocessing, model selection, prompt engineering, and deployment strategies. Vector databases are a powerful piece of the puzzle, but they are not the entire solution.
One of the recurring issues with LLMs and AI as a whole is the tradeoff in accuracy. For ages, computers have been binary and deterministic. Although vector databases may be a monumental step forward in knowledge exploration, they still need to be married to traditional structured architectures for the ultimate search experience. Some platforms such as Azure Cognitive Search and Elastic Search are actively working and fine-tuning hybrid searches using reciprocal rank fusion (RRF) to mix resulting ranks. Elastic is also addressing other vector database issues such as privacy of data and role-based access control (RBAC). On the prompt engineering side of things, various frameworks like guidance ai, Langchain, and LMQL are all being developed to provide a robust way of turning LLM data into meaningful structured responses. Needless to say, we are living in exciting times and emerging RAG architectures are only getting better each day.
At Osedea, we recognize the potential of vector databases, embeddings, and AI in driving transformative changes within organizations. Our comprehensive development services are designed to empower your organization in leveraging its data and fully realizing the potential of AI. Whether it's centralizing data, implementing vector databases, or navigating the complexities of AI adoption, Osedea is here to be your trusted partner on the path to data-driven success. Rest assured, we remain at the forefront of emerging technologies and are committed to staying on top of the latest advancements in the field.
What makes our team happy
Did you know that in 2012, the United Nations designated March 20th as the International Day of Happiness, highlighting its universal significance and integration into public policies for inclusive economic growth? Happiness plays a crucial role in our professional lives, as studies by the University of Oxford have shown a direct link to increased productivity. At Osedea, we firmly believe in the impact of happy team members. Rooted in diversity and inclusion, our corporate culture aims to create an environment where everyone can thrive. By continually seeking to integrate these principles to foster collaborators happiness, we demonstrate our commitment to their well-being, as they are our greatest asset.
Dreams come true initiative
Firstly, we find it important to recognize and support the individual aspirations of our team members. Thus, after two years of service within Osedea, we offer each member the privilege of realizing a personal project with a $5000 allocation and an additional week of vacation. This initiative, called "Dreams Come True," allows for a wide range of projects reflecting the unique aspirations and passions of our colleagues. Whether it's an epic journey around the world, immersion in a new culture, academic training to excel in a particular field, or even the realization of a long-dreamt entrepreneurial project, no ambition is too grand or audacious. What makes this initiative even more extraordinary is its renewal every five years, providing the team with the opportunity to continue nurturing its dreams and ambitions over time. In this article, we will also share some inspiring success stories from our colleagues, highlighting dreams that have become a reality thanks to this unique initiative at Osedea.
Enhanced long weekends
Moreover, we understand the rejuvenating and revitalizing effect long weekends can have on the morale and productivity. Hence, we've decided to extend these periods of rest by adding an extra day between Victoria Day in May and holidays in December. Upon reflection, this equates to offering an additional paid vacation week throughout the year, just in time to enjoy the mild and sunny weather. This initiative not only promotes the well-being of our members but also provides a valuable opportunity to unwind and recharge. At Osedea, we believe that a healthy work-life balance is essential for workplace well-being and satisfaction, which is why we are committed to offering benefits that support this balance and help our team members thrive both professionally and personally.
Workplace flexibility
Flexibility is a cornerstone of our culture and is reflected in each of our initiatives aimed at promoting our people's well-being. This notion is particularly important in light of recent studies. A 2023 report by the International Labour Organization revealed that increased flexibility, whether through staggered schedules, job sharing, or remote work options, leads to increased productivity and a better balance between work and personal life.
A global survey by Cisco of 28,000 full-time workers showed that 82% of them reported that the ability to work from anywhere made them happier. Furthermore, Gallup data has shown that optimal employee engagement occurs when they spend between 60% and 80% of their working time off-site. This group, which works remotely between 60% and 80% of the time, is also the most likely to strongly agree that their engagement needs related to development and relationships are being met.
At Osedea, we offer our collaborators a variety of options to suit their individual needs. Whether adopting a four-day workweek, working from anywhere in the world for up to six weeks, opting for full-time remote work, working at the office 100%, or in hybrid mode, we encourage flexibility and autonomy. We are confident that this approach allows our colleagues to find the perfect balance between work and personal life while promoting their engagement and growth within the company.
Building Families
For many people, starting a family is an essential life goal. However, the path to parenthood is often fraught with obstacles, whether due to infertility, sexual orientation, or financial constraints. At Osedea, we recognize these challenges and invest in inclusive and equitable social benefits that have a real impact on our collaborators' lives.
To support our team members on their journey to parenthood, regardless of their gender or sexual orientation, we have launched the "Building Families" program. This innovative program, focused on inclusion, fills the gaps in government programs, promotes equality, and offers choice, flexibility, and support tailored to each individual's path to parenthood. We are convinced that everyone deserves the support they need to start a family, and we are proud to offer this program as an expression of our commitment to equal opportunities and well-being. To learn more, read this article.
At Osedea, we place the happiness and well-being of our team members at the heart of our corporate culture. Through innovative and inclusive initiatives, we create an environment where everyone can thrive, both professionally and personally. We are convinced that happy colleagues are the key to our success. By listening to their needs, we will continue to innovate and improve our social benefits. We encourage our members to share their ideas to create an even more dynamic and rewarding environment. Together, let's cultivate a place where happiness, inclusion, and growth are essential.
Osedea portraits: through travels, reflections, and ambitions with Charles Ste-Marie
Embark on a journey with Charles Ste-Marie, a passionate individual whose experiences range from captivating travels across continents to navigating the ever-evolving landscape of the tech industry. As a dedicated member of the Osedea team, Charles shares his insights, reflections, and ambitions, providing a glimpse into his personal growth journey and the dynamic intersection of technology and human connection.
Which trip has had the biggest impact on you?
Finding the one trip that impacted me most is challenging. I believe each journey holds its value and brings something different from the last (or the next). My personal goal is to always be curious and open to discovering new countries and continue traveling.
Recently returning from a month in Vietnam, my first experience in Asia, I loved exploring this beautiful country. The breathtaking landscapes, rich history, and local cuisine captivated me. I recommend everyone to visit and appreciate the splendor of Halong Bay and the harmonious chaos of Hanoi.

In 2018, I spent four months in New Zealand, my first backpacking trip, and I loved every moment of it. Growing up listening to the Lord of the Rings trilogy, exploring the natural landscapes of the films and admiring the greatness of this beautiful country remain among my most cherished travel memories. It's rare to find a place where you can climb a snowy mountain in the morning and end up with your feet in the sand on the beach by the end of the day.
What aspect of your work at Osedea excites you the most and why?
The human aspect of my work is what excites me the most. Engaging in discussions around new projects with entrepreneurs, exploring new avenues for outdated technological solutions with beautiful Quebec and international companies, and daily exchanges with my colleagues connect me with one of Osedea's key values: "the important thing is to evolve together."
My role involves exploring innovative projects, with the ultimate goal of providing our clients with a superior technological solution.
If you could change one thing about the tech industry, what would it be and why?
At Osedea, we have the opportunity to discuss and explore a variety of technological innovations daily. However, I find that there are many barriers to entry for someone without extensive technical knowledge, despite a strong desire to learn. It's challenging to navigate through all technology spheres (especially with the rise of artificial intelligence).
My advice for someone like me, who may not have a technical background but has a desire to learn, is to remain curious, ask questions, and pursue some training (I completed the AWS Cloud Practitioner in 2023, which was an excellent way to gain a better understanding of the cloud universe as a whole). For more technical individuals, reaching out to those eager to learn and sharing your knowledge is the best way to move forward together.
What's the best lesson you've learned from a professional setback?
Throughout my career, there have been moments when it seemed like all the right doors were closing in front of me, and the opportunities I had hoped or worked so hard for were now inaccessible. A few years later, with a step back, I realized that just because one door closes doesn't mean I should stop working; on the contrary, that's when the right door will open.
It's through these "professional setbacks" that I developed an interest in the sales world and started working in young startups (MySmartJourney and MonClubSportif), where I learned a lot and honed my skills. These two jobs and the lessons learned from them allowed me to make the leap to Osedea almost two years ago.
What's your fondest memory at Osedea so far?
The OsedeaFest organized in the fall of 2023 is undoubtedly one of my fondest memories at Osedea. This two-day festival organized by our activity team was a great success in bringing everyone together, strengthening our bonds, and creating beautiful team memories. On the last day, an Amazing Race was organized in the Saint-Henri neighborhood, where Osedea's office is located. For nearly 4 hours, we were divided into teams of 4 to 5 people and had to complete a variety of challenges. I'm already looking forward to the 2024 edition!

From a work perspective, my month-long stay in France for Osedea was a golden opportunity. Combining international travel with my work has always been a personal and professional goal of mine.
What's the latest skill you've developed and how has it enhanced your work?
In recent months, I decided to further develop my skills in various areas at Osedea. I had the opportunity to work more on Boston Dynamics' Spot robot, so I set out to have a better understanding of Spot's different use cases and payloads (equipment that can be placed on the robot, such as a thermal camera, a lidar, etc.).
Specifically, the last training I took at Osedea was "Introduction to Generative AI" offered by Google Cloud. With the rise of AI and Generative AI, I wanted to have a better understanding of Generative AI as a whole and the different services offered by Google Cloud. More informally, I enjoy taking the time to discuss with my more technical colleagues to have a better understanding of our projects.
Where's your favorite place to find inspiration?
I've always loved working in cafes! Working 100% remotely from Quebec, stepping out of my house and settling into one of my favorite cafes allows me to be truly productive and tackle my to-do list. With several virtual meetings every day, blocking out a focused time in a cafe allows me to work without interruption. It's a way of optimizing my productivity that I've always valued, whether during my studies or now in my daily life at Osedea. Being a big coffee fan, it allows me to combine the useful with the pleasant.
What's your greatest professional ambition for the future?
I potentially would like to teach or give back in some way. Having been a hockey coach for a long time and more recently one of the coordinators of the University Laval's Commercial Missions program, I realized that I had a lot of fun and interest in sharing my knowledge and seeing improvement in young hockey players or students. In an ideal world, I would find a way to mix my interests in teaching, international experiences, and technology in a role. I'm not in a hurry to achieve this goal; for now, I have the desire to be in the field and learn every day, whether through training, professional experiences, or my colleagues around me.
What excites you most about the future of the tech industry?
The tech industry is constantly evolving, and the future is hard to predict. To me, that's the most exciting aspect of this technological ecosystem, that innovative ideas are growing everywhere and becoming more accessible (Artificial Intelligence, IoT, Augmented and Virtual Reality, Robotics, etc.). At Osedea, we make it our mission to be at the forefront of trends and to test these innovations. In Quebec, I'm excited to see the growth of our technological ecosystem. Over the past few years, I feel there is a desire to innovate, stand out, and continue building a technological ecosystem that is encouraging for startups, SMEs, as well as medium/large companies looking to optimize their technological processes. If I had to make a prediction for the coming years, I feel we will see an explosion of quantum innovations, growth in the battery ecosystem, and a continuation of projects/investments in AI.
Would you swap roles with a colleague at Osedea for a week, and why?
It has never crossed my mind to change roles at Osedea. What immediately appealed to me about our sales approach at Osedea is that the priority is always to bring exciting projects to our team. To meet these expectations, we must work closely with our colleagues from all departments to qualify, filter, and select the best projects. I feel lucky to be able to interact with my colleagues in AI and software engineering for one project, while the next conversation may focus on designing a new solution. If forced, I would switch to being a developer on our Spot robot. I find it extremely concrete as a use case and there is a "field" aspect to it that I really appreciate.
Leveraging Chain-of-thought to communicate with language models efficiently
Over a month ago we hosted our first AI hackathon at Osedea. Since the event, we've been on a quest to unlock the full prompting potential of GPT. As we witnessed the incredible capabilities of this large language model during the hackathon, we became obsessed with harnessing its power to deliver the most accurate and insightful results. This led us down the “Prompt Engineering” rabbit hole.
This article will share some of the knowledge we learned during our Hackathon and our outlook for the future. This way you can find easy and digestible information on the topic in one place, from our perspective.
With the rise in popularity of ChatGPT, prompt engineering has gained traction as a promising concept in artificial intelligence, particularly in natural language processing. This approach aims to align AI behavior with human intent. Prompt engineers carefully construct prompts to push generative AI models to their limits, resulting in improved performance and better outcomes for existing generative AI tools. Before delving into some of the techniques of prompt engineering, let's first provide a brief overview of how large language models (LLMs) operate.
So, how do language models actually work?
Language Models (LMs), including Large Language Models (LLMs) powering chatbots like ChatGPT, are probabilistic models designed to identify and learn statistical patterns in natural language. At their core, LMs calculate the probability of a word appearing at the end of a given input sentence. These models have been utilized for quite some time, even in everyday applications such as predictive texting on smartphones, where suggestions for the next words are provided based on the input.
The primary distinction between LMs and LLMs lies in the size of the model. With recent advancements in machine learning architectures and distributed training, developers can now train LLMs on a significantly larger scale. This increased size enhances the statistical accuracy of the model. (Although this is a simplification of how LLMs work, it's important to note that there are other factors at play, such as fine-tuning and reinforcement learning).

Lack of reasoning in LLMs
While LLMs excel at prediction, it's essential to understand that they do not possess true intelligence or reasoning capabilities. LLMs are essentially large prediction machines and lack the ability to think or reason behind their output. For instance, if I asked it to generate a sentence that ends with the same word it started with, an LLM like GPT-3 would struggle to fulfill the request.

This example demonstrates that LLMs, including ChatGPT, rely heavily on the statistical patterns they've learned and lack genuine understanding or reasoning.
Hallucinations
What we see in the example response above is also known as a hallucination. Hallucinations refer to confident responses generated by a model that are not supported by its training data. Also known as confabulation or delusion, these hallucinations occur when an algorithm ranks a response with high confidence, despite it being unrelated or incorrect. This phenomenon arises due to the LLM's limitations and is not contextualized as a weakness of the model. Hallucinations highlight the importance of caution when relying on AI models for factual answers that require reasoning, as they may provide misleading or inaccurate information.
Emergent abilities
In the example above, GPT-4 was asked the same question, although this time, it answered correctly to the prompt as opposed to GPT-3. Emergent abilities are an intriguing phenomenon observed in Large Language Models (LLMs) as they grow in size and complexity. Researchers have noticed that as LLMs, such as GPT-4, are trained on larger amounts of data with more parameters, they begin to exhibit new behaviors that go beyond their expected capabilities. This development of new abilities can be likened to unlocking superpowers, such as translation, coding, and even understanding jokes.
It’s both fascinating and somewhat concerning, as these emergent abilities are not explicitly programmed into the models but rather emerge through the learning process from vast amounts of text data. OpenAI's paper on GPT-4, titled "Sparks of AGI" delves into the details of these newfound capabilities and the signs of general intelligence they exhibit. However, despite these emergent abilities, the fundamental challenge of reasoning in LLMs still persists. As we continue to scale language models, we can expect more unexpected effects and capabilities to emerge, shaping the landscape of AI in exciting and unpredictable ways.
Now that we know the basics of LLMs, let’s take a look at prompt engineering.
What is prompt engineering?
Prompt engineering is an emerging discipline that focuses on the development and optimization of prompts for efficient use of language models (LMs). It serves as a crucial approach for understanding the capabilities and limitations of large language models and enhancing their performance across various tasks, such as question answering and arithmetic reasoning. Through prompt engineering, researchers and developers employ a range of techniques to design effective and robust prompts that interact with LLMs and other tools.
This discipline plays a vital role in expanding the capacity and applicability of LLMs across diverse applications and research topics. Some notable prompting techniques include Zero-Shot Prompting, Few-Shot Prompting, Chain-of-Thought Prompting, Self-Consistency, Generate Knowledge Prompting, Automatic Prompt Engineer, Active-Prompt, Directional Stimulus Prompting, ReAct Prompting, Multimodal CoT Prompting, Tree-of-Thoughts Prompting, and Graph Prompting. As prompt engineering continues to evolve, new techniques are being developed regularly, reflecting the ongoing efforts in this field. Let’s go over a few techniques in more detail.
Zero-shot prompting
Zero-shot prompting is a straightforward technique in prompt engineering that leverages the inherent capabilities of LLMs. With zero-shot prompting, it is possible to achieve accurate results without explicitly providing detailed instructions. For instance, when prompted for sentiment analysis without explicitly defining what sentiment is, GPT demonstrates its understanding by generating an accurate sentiment analysis response. This showcases GPT's ability to reply correctly "out of the box" based on its built-in understanding of sentiment.
Few-shot prompting
Few-shot prompting takes prompt engineering a step further by incorporating example outputs alongside the prompt. This approach enables in-context learning and guides the model towards improved performance. In the provided example, we observe a one-shot approach where the model learns to perform the task based on just a single example. However, we can enhance the prompt by scaling it with more examples, leading to more accurate responses from the model. By tweaking the prompt and utilizing these techniques, we can clearly observe the effects on the desired output. It is worth noting that for more challenging tasks, increasing the number of demonstrations, such as 3-shot, 5-shot, 10-shot, and so on, can be experimented with to further improve the model's performance.

Chain-of-thought prompting (CoT)
Chain-of-thought prompting is a technique used to enhance the reasoning abilities of large language models (LLMs). The idea behind this approach is to guide the LLMs by demonstrating the steps involved in solving a specific problem, similar to teaching a toddler how to do math. Instead of expecting direct answers, the LLMs are shown the process to reach the solution. By providing a chain of thought as an example, the LLMs learn to generate their own reasoning process, leading to more accurate outputs.

In 2022, researchers at Google published a paper on chain-of-thought prompting, highlighting its impact on prompt results. They conducted experiments using benchmarks for arithmetic reasoning abilities in LLMs and observed significant improvements when employing chain-of-thought prompting. The results showed higher scores for reasoning tasks compared to standard prompting methods. It was also noted that chain-of-thought prompting is an emergent ability in larger language models, indicating the evolving nature of prompting techniques and their dependence on model size.

While chain-of-thought has demonstrated positive results, it’s not without limitations. Certain tasks may still pose challenges for LLMs, and further improvements are needed to enhance their performance. However, the empirical gains achieved through chain-of-thought prompting have showcased its potential to enhance reasoning abilities in LLMs, surpassing even fine-tuned models. As the field of prompt engineering continues to evolve, it is expected that new approaches and techniques will further refine the capabilities of language models in the future.
Self-consistency with chain-of-thought
On top of CoT, we can add a technique called self-consistency which refers to a technique that involves creating an average of the results obtained from multiple iterations of a chain of thought prompt. Unlike other techniques mentioned previously, this approach does not focus on the prompt itself but rather on generating diverse answers by repeating the same 1-shot chain-of-thought prompt multiple times.

In the example above, by examining the most consistent answer among the three iterations, you can arrive at a valid result, which in this case is 9.
Tree-of-thought
A recently emerged technique called the "Tree of Thoughts" has gained prominence in self-consistent chain-of-thought prompting. ToT addresses the limitations of language models in problem-solving tasks. Since models make decisions based on individual tokens in a left-to-right manner, it restricts their effectiveness in tasks involving exploration and strategic planning.

To overcome these limitations, the ToT framework extends the "Chain of Thought" approach. It allows language models to consider coherent units of text called "thoughts" as intermediate steps in problem-solving. With ToT, models can make deliberate decisions by exploring different reasoning paths, evaluating choices, and determining the best course of action. They can also look ahead or backtrack when necessary to make more informed choices.
ReAct (Reason + Act)
And finally, we have ReAct, short for "Reason and Act". It’s a popular technique that leverages language models to generate both reasoning traces and task-specific actions. It enables LLMs to not only provide their thoughts and insights but also perform actions that interact with external sources such as databases, environments, or APIs.
With ReAct, LLMs gain access to tools like web browsers with Puppeteer, file systems, or any desired API. This access allows them to utilize external resources for tasks like web searching or retrieving information from knowledge bases. The generated reasoning traces help LLMs induce, track, and update action plans while handling exceptions.
By incorporating external tools and generating task-specific actions, ReAct enhances the LLMs' understanding of the task at hand and facilitates the retrieval of accurate and reliable information.
What can we do with prompt engineering?
Are you excited? Now that we have learned about these fascinating prompt engineering techniques, let's explore how we can make the most of them. The good news is that you don't have to become an expert in these techniques. Understanding the basics is sufficient because there are powerful tools available that implement these techniques seamlessly. One such leading framework in the field of prompt engineering is called Langchain.

Langchain, a Python and TypeScript framework launched last October, provides all the essential building blocks to leverage the capabilities of large language models effectively.Langchain integrates with a wide range of major model providers, including OpenAI, HuggingFace, Google, and others. These integrations are incredibly convenient as they allow for easy swapping of language models, enabling you to test out different behaviors across various providers.Furthermore, Langchain offers support for an extensive list of tools that agents can interact with. From search engines to AWS Lambdas and Twilio, you can also integrate your custom tools and models effortlessly using the same interface.
The framework also provides a variety of toolkit agents out of the box, catering to different purposes. For instance, SQL agents and JSON agents handle structured data independently, allowing multiple agents to interact with each other seamlessly.
Langchain is divided into seven modules: models, prompts, memory, indexes, chain, agents, and callbacks. By leveraging these modules, you can rapidly build powerful applications. For example, with just a few lines of code, you can create a tool that consumes PDFs and summarizes their content. Langchain empowers you to build customized applications, not limited to any specific language model like GPT-4.
Final thoughts
As we conclude our exploration of prompt engineering and its role in advancing language models, we are reminded of the ever-changing nature of the AI landscape. At Osedea, we are committed to staying at the forefront of this dynamic field, and we actively foster an environment of continuous learning, collaboration, and innovation.
Whether it be by organizing AI hackathons, conducting workshops or engaging in regular discussions around AI, these initiatives serve as opportunities for our team and other like-minded individuals to come together, challenge ourselves, and exchange ideas. By actively participating in these activities, we not only enhance our own capabilities, but also contribute to the collective growth and development of AI.
In this fast-paced environment, collaboration, knowledge-sharing, and continuous learning are key. By fostering an environment that encourages exploration and innovation, we can collectively navigate the evolving AI landscape and unlock new frontiers of possibility.
While we anticipate significant advancements in AI technologies in the coming months and years, it's important to remain adaptable. The availability of tools and frameworks today serves as a testament to the potential and possibilities that lie ahead. Let’s embrace the dynamic nature of AI and be prepared to harness the advancements that will shape our future.
Photo Credit: Mojahid Mottakin