Développement
Calculs informatiques avec Python


Dans mon article de blogue précédent, nous avons appris à nettoyer les données avec Python Pandas. Aujourd'hui, nous allons explorer l'un des outils clés largement utilisés pour le traitement des données et les calculs intensifs.
Python est l'un des langages les plus populaires pour l'analyse et le développement de données, car il est rapide pour les tests et le codage. Cependant, ce langage de haut niveau, dynamiquement typé, est quelque peu lent pour les tâches informatiques avancées/complexes.
Pour tirer meilleur partie des deux mondes (temps de développement et d’exécution de code rapide) : NumPy entre en jeu.
Dans cet article, nous allons passer en revue certaines des fonctions de base de NumPy et comment les utiliser efficacement lorsque vous travaillez avec un grand jeu de données. Nous verrons également la différence entre Pure Python et NumPy. Enfin, nous apprendrons quelques stratégies pouvant accélérer le code avec NumPy.
Introduction à NumPy
Qu'est-ce que NumPy ?
NumPy est une bibliothèque pour le langage de programmation Python utilisée pour travailler avec des tableaux multidimensionnels. NumPy signifie « Python numérique ». Il fournit un objet tableau multidimensionnel de hautes performances et des outils pour travailler avec ces tableaux.
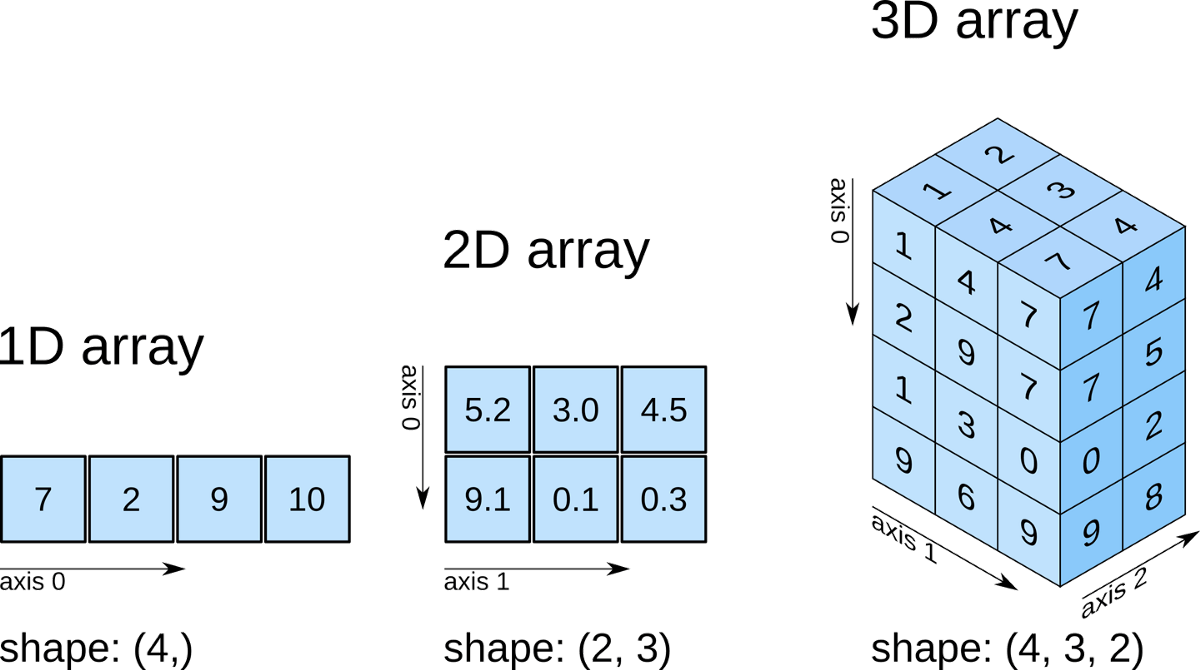
NumPy est une bibliothèque Python de base pour le calcul scientifique. Avec lui, nous pouvons effectuer des opérations mathématiques et logiques complexes plus rapidement et plus facilement, telles que des :
- Multiplication vecteur-vecteur
- Matrice-matrice et multiplication matrice-vecteur
- Opérations élémentaires sur des vecteurs et des matrices (c'est-à-dire additionner, soustraire, multiplier et diviser par un nombre)
- Comparaisons élément par élément ou par tableau
- Application de fonctions élément par élément à un vecteur/matrice (comme pow, log et exp)
- De nombreuses opérations d'algèbre linéaire peuvent être trouvées dans NumPy.linalg
- Réduction, statistiques, Suite.
Démarrage rapide avec NumPy
Jetons un coup d'œil à quelques exemples pour mieux le comprendre.
1. Création des tableaux
Avec Numpy, nous pouvons créer des tableaux multidimensionnels :
import numpy as np
# Create a 1-D Array
arr = np.array([1, 2, 3, 4, 5])
print(arr)
# Create a 2-D Array
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr)
# Create a 3-D Array
arr = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
print(arr)
Sortie:
array([1, 2, 3, 4, 5])
---
array([[1, 2, 3],
[4, 5, 6]])
---
array([[[1, 2, 3],
[4, 5, 6]],
[[1, 2, 3],
[4, 5, 6]]])
2. Indexation des tableaux
L’indexation des tableaux est similaire aux listes Python:
arr = np.array([1, 2, 3, 4])
# Get the first element from the array
print(arr[0])
# Get third and fourth elements from the array and sum them.
print(arr[2] + arr[3])
Sortie:
1
---
7
3. Array Slicing
Nous pouvons obtenir une tranche d'un tableau comme ceci : [start:end].
arr = np.array([1, 2, 3, 4, 5, 6, 7])
# Slice elements from index 1 to index 5 from the array
arr[1:5]
Sortie:
array([2, 3, 4, 5])
4. Forme du tableau
La forme d'un tableau est le nombre d'éléments dans chaque dimension. Nous pouvons obtenir la forme actuelle d'un tableau comme ceci :
# Create a 2-D array
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
print(arr)
# Get the shape
print(arr.shape)
Sortie:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
---
(2, 4)
(2, 4) signifie que le tableau à deux dimensions, la première dimension a deux éléments et la seconde en a quatre.
5. Remodeler les tableaux
Remodeler un tableau de 1-D à 2-D
# Create a 1-D array
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
print(arr)
# Convert the 1-D array with 12 elements into a 2-D array. The outermost dimension will have 4 arrays, each with 3 elements
new_arr = arr.reshape(4, 3)
print(new_arr)
Sortie:
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
---
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
Pour plus de détails, consultez la documentation NumPy.
Listes Python vs tableaux NumPy
Une question surgit régulièrement : quelle est la vraie différence entre les listes Python et les tableaux NumPy? La réponse simple est la performance.
Pourquoi NumPy est-il plus rapide ?
Python à certaines lacunes qui diminuent sa performance, tels que la vérification de type et le comptage de références, qui s'accumulent pour chaque opération et peuvent devenir particulièrement importants dans une grande boucle.
Ce que fait NumPy, c'est qu'il pousse ces opérations de boucle vers le bas dans le code compilé, de sorte que la vérification de type ne doit avoir lieu qu'une seule fois pour toute la boucle, donc elles peuvent être effectuées plus rapidement.
Dans l'ensemble, NumPy fonctionne mieux dans les cas suivants :
- Taille - NumPy utilise beaucoup moins de mémoire pour stocker les données.
- Performance - Les tableaux NumPy sont plus rapides que les listes Python.
- Fonctionnalité - NumPy a optimisé des fonctions mathématiques intégrées qui sont pratiques à utiliser.
Consommation - mémoire
Pour allouer une liste de 1000 éléments, Python prend 48000 octets de mémoire, alors que NumPy n'a besoin que de 8000 octets. Quelle amélioration significative !
import numpy as np
import sys
# Declaring a Python list of 1000 elements
ls = range(1000)
print(f"Size of each element of the list: {sys.getsizeof(ls)} bytes.")
print(f"Size of the list: {sys.getsizeof(ls)*len(ls)} bytes.")
# Declaring a Numpy array of 1000 elements
arr = np.arange(1000)
print(f"Size of each element of the array: {arr.itemsize} bytes.")
print(f"Size of the array: {arr.size*arr.itemsize} bytes.")
Sortie:
Size of each element of the list: 48 bytes.
Size of the list: 48000 bytes.
Size of each element of the array: 8 bytes.
Size of the array: 8000 bytes.
Performances
Il existe une grande différence de performances. Si nous ajoutons 5 à chaque élément d'une liste de 100k valeurs :
# Python way
ls = list(range(100000))
%timeit [val + 5 for val in ls]
# Numpy way
arr = np.array(ls)
%timeit arr + 5
Sortie:
6.17 ms ± 35.9 µs per loop
---
34.8 µs ± 340 ns per loop
Il s'est avéré qu'il fallait environ 6 millisecondes (pouvant varier en fonction des différentes machines) pour que Python traite chaque boucle, alors que NumPy ne prenait que 34 microsecondes par boucle. Nous avons environ 200 fois plus de vitesse en supprimant les boucles en Python.
Stratégies pour accélérer le code avec NumPy
Nous avons maintenant appris que NumPy est un outil puissant pour travailler avec de grands tableaux. Cependant, ce n'est pas seulement utile pour le calcul scientifique. Cela peut également être pratique pour certaines tâches de développement de logiciels/services qui impliquent un traitement de données complexe avec un grand jeu de données. Avec Pure Python, nous ferions normalement une boucle sur l'ensemble des données ce qui n'est… pas si optimal, n'est-ce pas ?
Afin d'y parvenir efficacement, voyons de quoi NumPy est capable et comment nous pouvons l'utiliser pour accélérer notre code.
Débarrassons-nous de ces boucles lentes !
- Ufuncs
- Aggregations
- Slicing, Masking and Fancy indexing
Ufuncs
Ufuncs, abréviation de fonctions universelles, propose un ensemble d' opérateurs qui opèrent élément par élément sur des tableaux entiers.
(Pour en savoir plus sur Ufuncs, voir les bases des fonctions universelles)
Par exemple, nous voulons ajouter les éléments de la liste a. et b. Sans NumPy, nous pouvons utiliser la méthode intégrée zip():
a = list(range(1001)) # [0, 1, 2, 3, ..., 999, 1000]
b = list(reversed(range(1001))) # [1000, 999, 998, ..., 1, 0]
c = [i+j for i, j in zip(a, b)] # returns [1000, 1000, ..., 1000, 1000]
Au lieu de boucler la liste, nous pouvons simplement utiliser le add()de Numpy ufunc:
import numpy as np
a = np.array(list(range(1001)))
b = np.array(list(reversed(range(1001))))
c = np.add(a, b) #returns array([1000, 1000, ..., 1000, 1000])
Comparons le temps d'exécution:
%timeit [i+j for i, j in zip(a, b)]
%timeit np.add(a, b)
Sortie:
61 µs ± 4.11 µs per loop
---
811 ns ± 29.8 ns per loop
On observe une différence significative, nous sommes 75 fois plus rapides avec la version NumPy et le code semble beaucoup plus propre. N'est-ce pas génial?
Il existe de nombreuses autres ufuncs disponibles:
- Arithmétique :
+,-,*,/,//,%… - Comparaison :
<,>,==,<=,>=,!=… - Bitwise:
&,|,~,^… - Fonctions trigonométriques:
np.sin,np.cos,np.tan… - Et plus encore…
Agrégations
Les agrégations sont des fonctions qui résument les valeurs dans un tableau (par exemple min, max, somme, moyenne, etc.).
Voyons combien de temps il faut à une boucle Python pour obtenir la valeur minimale d'une liste de 100 000 valeurs aléatoires.
Avec Python intégré min():
from random import random
ls = [random() for i in range(100000)]
%timeit min(ls)
Avec les fonctions d'agrégation NumPy min():
arr = np.array(ls)
%timeit arr.min()
Sortie:
1.3 ms ± 7.59 µs per loop
---
33.6 µs ± 248 ns per loop
Encore une fois, le processus est 40 fois plus rapide et ce, sans écrire une seule boucle avec NumPy !
De plus, les agrégations peuvent également fonctionner sur des tableaux multidimensionnels:
# Create a 3x5 array with random numbers
arr = np.random.randint(0, 10, (3, 5))
print(arr)
# Get the sum of the entire array
print(arr.sum())
# Get the sum of all the columns in the array
print(arr.sum(axis=0))
# Get the sum of all the rows in the array
print(arr.sum(axis=1))
Sortie:
array([[7, 7, 5, 1, 9],
[8, 7, 0, 2, 4],
[0, 5, 6, 4, 0]])
---
65
---
array([15, 19, 11, 7, 13])
---
array([29, 21, 15])
Il existe d'autres fonctions d'agrégation :
- somme
- moyenne
- produit
- médiane
- variance
- argmin
- argmax
- Et plus
Découpage, masquage et indexation fantaisie (fancy indexing)
Nous venons de voir comment découper et indexer des tableaux NumPy plus tôt. En fait, NumPy propose d'autres moyens plus rapides et plus pratiques :
Masquage
Avec les masques, nous pouvons indexer un tableau avec un autre tableau. Par exemple, nous voulons indexer un tableau avec un masque booléen. Ce que nous obtenons, c'est que seuls les éléments qui s'alignent avec True dans ce masque seront retournés (render):
# Create an array
arr = np.array([1, 2, 3, 4, 5])
print(arr)
# Create a boolean mask
mask = np.array([False, False, True, True, True])
print(arr[mask])
Sortie:
array([1, 2, 3, 4, 5])
---
array([3, 4, 5])
Ici, nous n'obtenons que [3 4 5], car ces valeurs s'alignent avec True dans le masque.
Maintenant, vous pourriez être un peu confus et vous demander pourquoi nous aurions besoin de cela ? Là où les masques deviennent utiles, c'est lorsqu'ils sont combinés avec des ufuncs. Par exemple, nous voulons obtenir les éléments d'un tableau en fonction de certaines conditions. Nous pouvons indexer ce tableau en utilisant un masque avec les conditions :
# Create an array
arr = np.array([1, 2, 3, 4, 5])
print(arr)
# Create a mask
mask = (arr % 2 ==0) | (arr > 4)
print(arr[mask])
Sortie:
array([1, 2, 3, 4, 5])
---
array([2, 4, 5])
Et les valeurs qui répondent aux critères seront renvoyées.
Indexation Fantaisie
L'idée de l'indexation fantaisie est très simple. Elle nous permet d'accéder à plusieurs éléments d'un tableau à la fois en utilisant un tableau d'indices.
Par exemple, nous obtenons les 0e et 1er éléments du tableau arr en utilisant un autre tableau d’indices :
arr = np.array([1, 2, 3, 4, 5])
index_to_select = [0, 1]
print(arr[index_to_select])
Sortie:
array([1, 2])
Lorsque l'on combine tout cela ensemble :
- Accéder aux tableaux multidimensionnels par [
ligne
- ,
colonne
- ]:
# Create a 2x3 array
arr = np.arange(6).reshape(2, 3)
print(arr)
# Get row 0 and column 1
print(arr[0, 1])
# Get all rows in column 1 (Mixing slices and indices)
arr[:, 1]
Sortie:
array([[0, 1, 2],
[3, 4, 5]])
---
1
---
array([1, 4])
- Masquage des tableaux multidimensionnels :
# Create a 2x3 array
arr = np.arange(6).reshape(2, 3)
print(arr)
# Masking the entire array
mask = abs(arr-3)<2
print(arr[mask])
Sortie:
array([[0, 1, 2],
[3, 4, 5]])
---
array([2, 3, 4])
- Mixing, masking and slicing:
arr = np.arange(6).reshape(2, 3)
print(arr)
mask = arr.sum(axis=1) > 4
print(arr[mask, 1:])
Sortie:
array([[0, 1, 2],
[3, 4, 5]])
---
array([[4, 5]])
Toutes ces opérations NumPy peuvent être combinées de manière presque illimitée !
Conclusion
Quelle que soit la taille de votre jeu de données ou la complexité des opérations que vous devez effectuer avec vos données, les fonctions NumPy sont là pour vous rendre la tâche plus facile et rapide.
Résumons ce que nous avons couvert :
- L'écriture de Python est rapide, mais les boucles sont lentes pour le calcul de grands ensembles de données.
- NumPy est un excellent outil à utiliser ! Il pousse des boucles dans sa couche compilée, nous obtenons donc:
- Un temps de développement plus rapide
- Un temps d'exécution plus rapide.
- Stratégies pour accélérer votre code :
- Ufuncs - Pour les opérations élémentaires.
- Agrégations - Pour la synthèse de tableaux
- Tranchage, masquage et indexation fantaisie - Pour sélectionner et opérer rapidement sur des tableaux.
Vous cherchez le code source final!
Références
- Cours Python - Tutoriel NumPy
- NumPy Documentation

Cet article vous a donné des idées ? Nous serions ravis de travailler avec vous ! Contactez-nous et découvrons ce que nous pouvons faire ensemble.






