Développement
La gestion du dataset pendant la phase de mise en place


Un projet de machine learning (ML) comporte plusieurs étapes importantes dont : la définition des objectifs du projet ou de la problématique qu’on cherche à résoudre, la mise en place d’un dataset adéquat, la phase de travail sur le modèle, la mise en production et le monitoring. Nous y reviendrons plus tard dans un autre article. La phase qui nous intéresse aujourd' hui est celle de la mise en place du dataset et, surtout de sa gestion.
En effet, construire le dataset qui servira pour l'entraînement du modèle est une phase importante, je dirais qu’elle est la plus importante d'un projet, car c'est cette phase qui définit la manière dont notre modèle sera construit (en matière d’inputs). Pendant cette phase on fait donc face à plusieurs problèmes dont :
- Le choix du type de la donnée selon le problème que l'on souhaite résoudre
avec le modèle ML; - La manière dont ces données seront présentées et structurées ou présentées au modèle pendant son apprentissage;
- La manière dont ces données seront stockées.
Pour ce dernier problème, il existe plusieurs solutions.
Nous pouvons citer entre autres : les solutions de stockage sur cloud dont Drive, AWS... et bien d’autres encore qui existent sur le marché lorsqu’on n’a pas les moyens de s’offrir ces grands volumes de stockage sur cloud. On pense notamment au stockage en local et sur des disques durs (comme c’est le cas quand on est étudiant).
Ces nombreux outils de stockages sont intéressants, mais ils n’offrent pas tous la possibilité de faire du versionning de data, comme Git nous aide pour faire du versionning de code (qui est sa spécificité première). Aussi, ces outils n'offrent pas la possibilité d'être utilisé de manière aussi basique que l’est Git. Ici, nous faisons référence à des phases telles que :
- Télécharger le contenu de notre dataset stocké sous forme de zip.
- Dézipper le fichier.
- Mettre à jour le dataset utilisé pour faire apprendre au modèle.
- Uploader de nouvelles données sur le stockage cloud lorsque nous en avons.
- S’assurer de ne pas avoir des données en double sur ce dernier, ce qui n’est d'aucune utilité surtout lorsque nous payons pour ce volume de stockage.
- Devoir répéter cette tâche dès qu’on améliore notre dataset ou lorsqu’on change d'ordinateur pour travailler sur le même projet.
C’est pour cela qu’utiliser des outils pratiques qui peuvent faire ces contrôles à notre place et s'assurer de la conformité de nos données utilisées peut-être utile et surtout nous faire gagner du temps (être ingénieur en informatique, c'est aussi la simplicité et parfois la facilité, tel est mon crédo).
C’est dans cette recherche de simplicité que je vous présenterai dans cette série d’articles deux outils que j’ai découverts qui sont d’une extrême force et qui peuvent vous être utiles. Ces deux outils sont Data Version Control (DVC) et Rclone. Je présenterai DVC, dans ce premier article, en faisant une brève présentation de l’outil, de l'installation, des commandes basiques qui vous permettront de gérer vos données efficacement et de mon opinion sur cet outil.
1 - Présentation de Data Version Control
Data Version Control est un outil de gestion de données et d’expériences ML qui tire parti de l’ensemble d’outils de versionning existants et de pratiques d’ingénierie dans le but de simplifier la mise en place des projets ML, de la phase de construction du dataset jusqu’à sa phase de déploiement et de monitoring (https://dvc.org/doc). Il peut être utile, entre autres, dans les cas d'utilisation suivants :
- Le suivi et l’enregistrement des données et des modèles ML de la même manière que le suivi de code;
- La création et le basculement facile entre les versions de données et de modèles;
- La comparaison des métriques de deux modèles (nous verrons celà dans un prochain article);
- L'adoption d’outils d'ingénierie et de meilleures pratiques dans les projets de sciences de données.
Vous vous doutez bien qu’avec toutes ces caractéristiques, DVC peut être un grand atout dans la gestion des projets ML et s’intégrer facilement dans un processus MLOps qui devient une thématique importante actuellement.
2 - Installation de DVC
DVC peut être utilisé sur différents systèmes d’exploitation (macOS, Windows, Linux) et sur divers environnements (virtuels ou non) selon celui que vous préférez. Si vous aimez la simplicité comme moi, vous opterez pour la méthode d’installation basique qui est (si vous avez installé Python) :
pip install dvc
Obtenez plus de détails sur les options d’installation en suivant le lien https://dvc.org/doc/install. À présent que DVC est installé, passons à ce qui nous intéresse, soit la gestion des données.
3 - Commandes basiques pour la gestion de données
Présenter DVC dans sa totalité nous prendrait beaucoup de temps. Cependant, nous pouvons nous concentrer sur les commandes utiles pour récupérer vos données mises sur votre stockage cloud. Pour cela vous êtes
servis, car DVC peut être utilisé avec :
- Amazon S3;
- Google Drive ;
- Google Cloud Storage;
- Local remote;
- Et bien d’autres encore (https://dvc.org/doc/command-reference/remote/add).
Nous utiliserons le stockage Google Drive dans notre cas d'utilisation, tirant ainsi parti des outils d'ingénierie existants, comme Git, DVC offre une panoplie de commandes similaires qui, à coup sûr, vous feront plaisir.
3.1 - Initialisation du répertoire
Comme avec Git, vous devez initialiser le répertoire, histoire de lui préciser que vous utiliserez DVC dans ce dernier. Ainsi la commande est :
dvc init --no-scm
Notons que l'option --no-scm est utile quand votre répertoire n'est pas utilisé par un outil de versionning. Vous aurez donc le résultat suivant dans votre dossier :

Ce qui est fortement similaire à Git avec le .dvc et le .dvcignore pour ignorer les dossiers et fichiers que vous ne souhaitez pas soumettre à votre stockage drive, dans un projet ML, ça pourrait être le code écrit, le modèle obtenu ou les fichiers de configuration et d'environnement.
3.2 - Création d’un dossier pour notre dataset
Il serait beaucoup plus pratique d’avoir votre dataset dans un sous-dossier de votre répertoire de travail. Pensez donc à créer un dossier pour ce dernier et ajoutez-y vos données (images, audios, fichiers .csv selon votre projet).
Sous Linux, faites un :
mkdir data
3.3 - Ajoutez vos données à votre .dvc et faites un commit pour conserver un snap actuel
Maintenant, ajoutez vos données à DVC avec la commande :
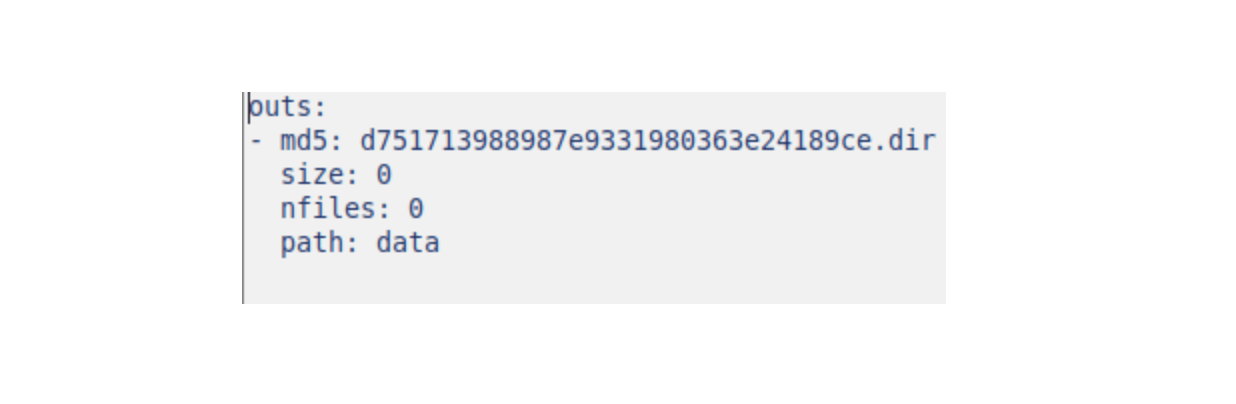
dvc add data
Et faites un commit pour conserver votre stage :
dvc commit
Votre répertoire de travail se présente maintenant comme suit :
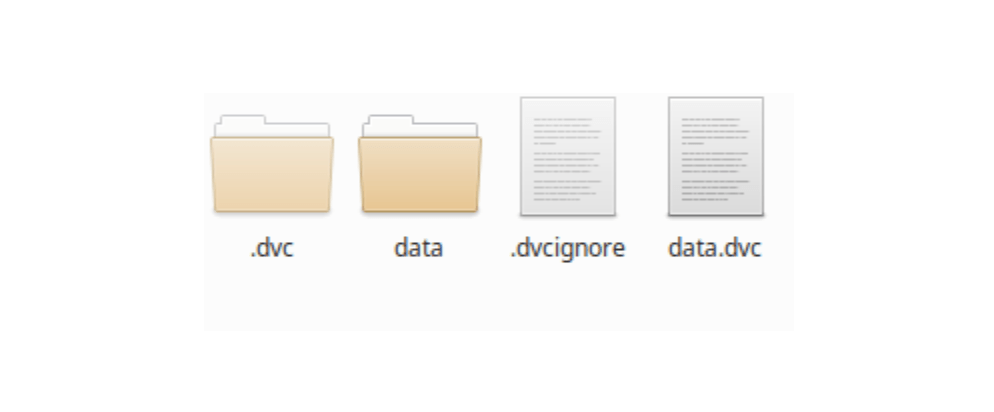
Le fichier que je trouve intéressant est le data.dvc qui conserve l’historique de vos ajouts et qui peut être partagé, surtout si plusieurs personnes ont accès aux données.
3.4 - Liaison du répertoire avec notre stockage cloud
Pour cette partie, vous aurez à utiliser la commande suivante :
dvc remote add -d nom_de_votre_remote url
Exemple :
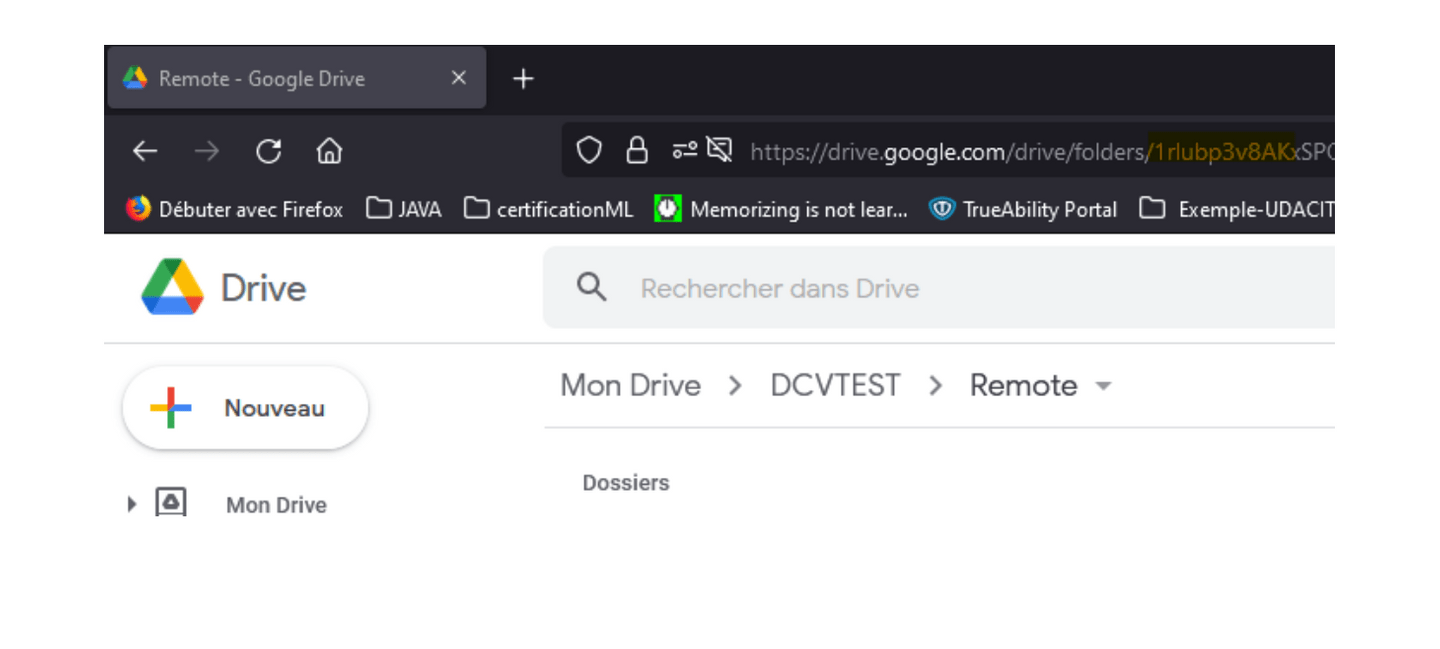
dvc remote add -d driveStore gdrive:Identifiant_dossier_sur_drive
Pour récupérer cet identifiant après avoir créé votre dossier sur votre stockage, vous n’avez qu’à le copier dans l’URL de votre navigateur : voir id en jaune sur l’exemple de la figure suivante.
Vous verrez un lien pour donner les autorisations à DVC, lisez-les et, si cela vous convient, vous pouvez continuer.
3.5 - Poussez votre dataset sur votre stockage
Et comme vous l’imaginez, la commande pour le faire est :
dvc push
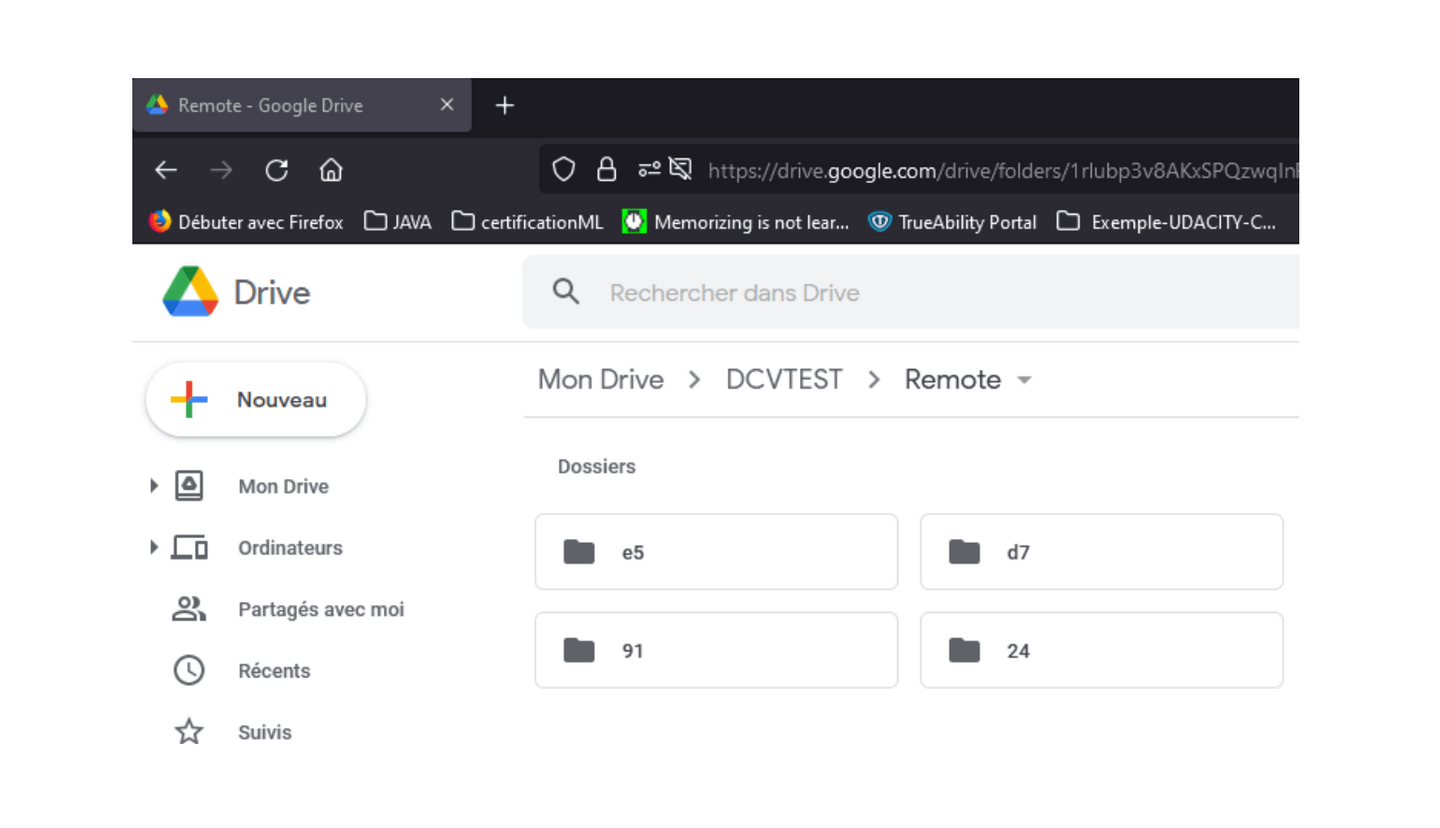
Vos données sont ainsi disponibles sur votre drive dans le dossier où vous avez lié votre répertoire local. Il est vrai que ces dernières ne reflètent pas exactement les données sur votre machine locale, mais soyez sûr que vos données y sont et nous reviendrons sur ce détail dans la dernière partie.
3.6 - Récupérez les données
Pour récupérer les données, pensez à la commande :
dvc pull
Dans le cas d’un dossier partagé, il faut penser à partager également le fichier data.dvc qui constitue en quelque sorte la clé de votre stockage remote. Ainsi, vos collègues devront faire les étapes suivantes après l’installation de DVC:
- dvc init --no-scm
- dvc remote add -d driveStore gdrive:Identifiantdossiersur_drive
- copier le data.dvc dans leur répertoire de travail
- dvc pull
3.7 - Les autres commandes
DVC ne se résume pas à la gestion de données et vous pouvez faire des choses encore plus intéressantes avec lui tout au long de votre projet ML. N’hésitez pas à utiliser l’aide disponible:
dvc --help
Consultez aussi les commandes disponibles pour les autres cas d’utilisation mentionnés plus haut sur le lien https://dvc.org/doc/command-reference.
4 - Mon avis sur DVC
Comme mentionné tout au long de cet article, DVC vous permet de faire plusieurs choses (voir les cas d’utilisation), notamment la gestion des données que nous avons parcourue ensemble dans ce premier article sur le sujet. Il est très facile d’utilisation, et ce, à partir de de son installation. Il permet aussi de facilement stocker et récupérer nos données au moyen de commandes simples très similaires aux commandes utilisées par Git. Cependant, il y a quelques points à souligner qui ne diminuent en rien l’efficacité de DVC. Il s’agit de la présentation de notre dataset sur notre dossier de stockage Drive qui peut être troublant. À cela s’ajoute le fait de devoir partager le data.dvc pour plus d'homogénéité entre les données. Bien évidemment, en combinant DVC à Git, le partage de ce fichier dans votre projet n’est qu'une simple affaire.
Nous voici à la fin de l’introduction à DVC que nous avons faite ensemble. Dans le prochain article nous parlerons de Rclone et le comparerons à DVC, et, qui sait, peut-être que Rclone nous enlèvera les quelques points d’ombre que nous avons actuellement. N’hésitez pas à consulter le site de DVC, à tester l’outil, à partager les expériences que vous avez eues en l'utilisant, et surtout à partager les autres outils de gestion de données et/ou de versionning de données que vous avez utilisés. Vos avis et vos commentaires sont également les bienvenus.
Crédit Photo : Grovemade

Cet article vous a donné des idées ? Nous serions ravis de travailler avec vous ! Contactez-nous et découvrons ce que nous pouvons faire ensemble.




.jpg)

