Développement

Comment détecter « les angles morts » de votre application TypeScript

Vous codez en TypeScript. Tout est beau. Vous avez dit adieu à l'infâme undefined is not a function de JavaScript et vous ne regrettez rien !
Et pourtant, une erreur s'affiche à votre écran :
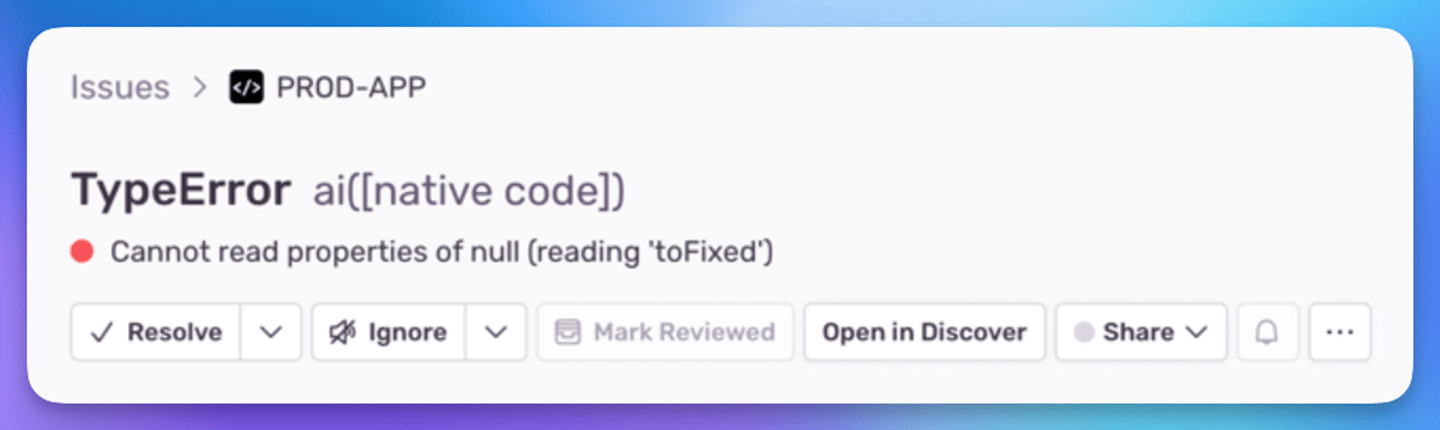
Un instant … comment est-ce possible?!
Vous pensez, en tant que développeur TS légitimement confus : comment une telle erreur a-t-elle pu passer inaperçue ? Est-ce que quelqu’un a utilisé any quelque part ?
Eh bien, non. Du moins, pas directement. C'est une bonne nouvelle.
La mauvaise nouvelle, c'est que vous avez certainement beaucoup … beaucoup plus d'angles morts dans votre application TypeScript. Et vous venez d'en découvrir un !

Des histoires comme celle-ci sont courantes. Parfois, elles peuvent avoir des conséquences terribles pour le produit, comme les unités principales Mazda qui ont été bloquées à cause d'une station NPR locale de Seattle en 2022 😅
Ces erreurs potentielles sont externes à votre logiciel, elles proviennent du « monde extérieur », chose qui ne se contrôle pas. Elles prennent différentes formes, mais ici je me concentrerai sur les 3 plus courantes :
- Les entrées clients
- Les réponses des API tierces
- L’extraction de données
Voyons comment aborder ces problèmes et ce qu'ils ont en commun.
Les angles morts sont partout
1. Les entrées clients
Le terme « Client » fait référence aux utilisateurs ou aux systèmes qui fournissent des entrées à votre système. Cela peut inclure :
- Un utilisateur final de votre application
- Une autre application qui utilise votre API
- Un développeur qui utilise votre CLI (Command-line interface)
Si vous avez le contrôle sur différents systèmes qui communiquent entre eux (par exemple, client <> serveur), vous devriez trouver un moyen de partager les types entre vos systèmes. tRPC est un excellent outil pour construire des API sûres sur le plan des types et obtenir une certaine sécurité du côté client. Il utilise également les techniques que je vous mentionne ci-dessous 😉
Maintenant, allez à la périphérie de vos systèmes et considérez les différents endroits où les utilisateurs externes vous fournissent des entrées au cours de la phase d’exécution (runtime).
Vous devez valider ces entrées en temps d’exécution
Vous connaissez peut-être déjà le dicton :
Ne jamais faire confiance aux entrées utilisateurs.

Il y a toujours un XKCD pertinent : https://xkcd.com/327/
Peu importe si l'utilisateur est malveillant, il y a une chose dont vous pouvez être sûr : TypeScript ne peut pas imposer les types sur les données en temps d'exécution. Vous devez valider ce qui entre dans votre système. Il est préférable que cela échoue rapidement si ça ne correspond pas aux types attendus.
Pour être plus précis, le type de l'entrée utilisateur est unknown. Vous souhaiteriez qu'il s'agisse d'un string ou qu'il suive une certaine interface d'objet. Mais vous ne pouvez pas obliger le client à faire ce qu'il faut. Quelque chose doit vérifier les données en temps d'exécution, et TypeScript ne peut le faire.
2. Réponses des API tierces
Il existe différents niveaux de confiance lorsque l’on travail avec une API externe :
🟢 Ils vous fournissent un « Typed SDK ».
🟡 Ils n'ont pas de « Typed SDK », mais ils ont une documentation en ligne !
🟠 Eh bien, ils ont une certaine forme de documentation dans un fichier .docx
🔴 Attendez, quelle documentation ? Oh, celle-ci est obsolète, désolé(e) !
La documentation des API tierces est facilement erronée, à moins qu'elle ne soit générée à partir du code source, ce qui, selon mon expérience, n'est pas chose courante. Pourtant, j'ai travaillé sur des projets TypeScript où les types de l'API externe étaient transcrits à partir de la documentation dans des fichiers .d.ts.
Imaginez tomber sur ce fichier asana.d.ts qui tente de compenser l’absence de SDK dans TypeScript :
// https://developers.asana.com/docs/taskexport interface AsanaTask { gid: string; resource_type: string; approval_status: 'pending' | 'approved' | 'rejected' | 'completed'; // …}
Eh bien, cela demanderait beaucoup de travail et d'optimisme.
En production, Asana peut rencontrer un problème et le champ resource_type peut manquer à l’appel lors de l’entrée d’une réponse. Pourtant, notre code s'attend à ce que ce champ soit présent. Et ainsi, cela brise nos « attentes »... et possiblement notre application à un moment ultérieur. Retour au pays du JavaScript.
Alors, que pouvez-vous faire ?
Vous devez valider les réponses des API tierces en temps d'exécution.
Puisque vous ne pouvez pas être certain que Asana se comportera comme « documenté » dans toutes les situations au moment de l'exécution, vous devez constamment vérifier. La plupart du temps, Asana se comportera comme prévu, mais, si ce n’est pas le cas, vous la détecterez immédiatement et vous empêcherez que ce problème ait des répercussions sur votre système.
3. Extraction de données depuis la BD
Cela peut être moins évident. Les bases de données sont fiables. Mais le sont-elles vraiment ?
Eh bien, comme pour tout ce qui est suffisamment complexe dans la vie : ça dépend™.
Encore une fois, cela dépend de votre niveau de confiance et donc de vos réponses au questions suivantes :
- Y a-t-il des schémas stricts pour les données stockées ? Pensez aux bases de données SQL par rapport aux bases de données NoSQL.
- Les schémas sont-ils liés à vos définitions de types? (La vérité dupliquée peut se désynchroniser)
- Les gens peuvent-ils modifier les données sans utiliser votre application?
- Y a-t-il des scripts qui peuvent mettre à jour les données sans utiliser votre application?
- Y a-t-il d'autres applications qui peuvent mettre à jour les données sans utiliser votre application?
Vous voyez, tous les types dans votre backend TypeScript ne peuvent pas empêcher un acteur externe de se connecter directement à votre base de données et de perturber les données. Si la protection du type n'est pas au niveau de la base de données, vous pourriez ne pas extraire les types auxquels vous pensez accéder.
Les bases de données SQL correctement construites inspirent plus confiance que les documents NoSQL qui peuvent stocker n'importe quoi.
Si, comme moi, vous utilisez Firestore en ce moment, sachez que n'importe quel client a un accès direct à votre « base de données cloud NoSQL évolutive ». La saisie du code à propos de ce qui devrait être extrait d'un abonnement peut entraîner des erreurs en production.
db .collection('ad-campaigns') .onSnapshot( (snapshot) => { const campaigns = snapshot.docs.map( // ❌ This may be false and you won't handle it! (d) => d.data() as Campaign[] ) setAdCampaigns(campaigns) } )
Que faire lorsque vous ne pouvez pas être sûr que votre base de données n’à pas été altérée ?
Vous devez valider les données extraites de la base de données en temps d'exécution.
Je suis sûr que vous commencez à comprendre le schéma ici 😉
Maintenant, voyons comment vous pouvez facilement valider les données en temps d'exécution...
Zod à la rescousse !
Théoriquement, la validation des données en temps d'exécution consiste à :
- Déclarer ce type de données comme étant de type
unknown - Vérifier le schéma des données et générer une erreur si ce n'est pas ce que vous attendiez
De cette façon, TypeScript s'assurera que nous ne formulons pas d'attentes que nous n'avons pas encore vérifiées.
app.get("/price", (req, res) => { const code = req.query.code as unknown; // We can't use code as a string here, TS would complain… if (typeof code !== 'string') { return res.sendStatus(400) } // Now we KNOW code is a string})
Nous pourrions le faire tout en construisant une collection de « helpers » qui réduisent le code redondant... ou nous pouvons utiliser une bibliothèque qui remplira cette tâche pour nous !
Il existe plusieurs bibliothèques de validation de données disponibles, telles que Joi ou Yup. Mais Zodest devenue assez populaire et a été conçue en premier lieu pour TypeScript.
L'utilisation de Zod pour valider les données se fait en 2 étapes :
- Définir le schéma
- L'utiliser pour analyser les données en temps d'exécution
app.get("/price", (req, res) => { const code = req.query.code as unknown; // We can't use code as a string here, TS would complain… if (typeof code !== 'string') { return res.sendStatus(400) } // Now we KNOW code is a string})
L'API Zod vous permet de déclarer un schéma de manière très similaire à la déclaration d'interfaces :
const userSchema = z.object({ username: z.string(), location: z.object({ latitude: z.number(), longitude: z.number(), }), strings: z.array(z.object({ value: z.string() })),});
Ainsi, vous pouvez commencer à définir le schéma et utiliser schema.safeParse(data) pour valider ce qui se passe au moment de l'exécution :
app.get("/users", (req, res) => { const result = userSchema.safeParse(req.query.user); // Fail early if (!result.success) { return res.status(400).json(toErrorResponse(result.error)) } const user = result.data // Now we KNOW user follows the schema…})
Et en ce qui concerne la duplication?
Vous l’aviez peut-être remarqué, mais vous avez maintenant dupliqué la source de vérité :
- Dans votre type
Userexistant - Dans votre nouvelle définition
userSchema

Vous voyez, Zod s'en occupe pour vous : il peut déduire le type à partir des schémas. Vous n'avez pas à maintenir les types et les schémas en parallèle, les types sont générés à partir des schémas :
type User = z.infer<typeof userSchema>// Now you can use this User type anywhere you need!
Et qu'en est-il de ma documentation d'API ?
Vous ne voulez pas être le fournisseur d'API tierces avec une documentation obsolète ? Super !
Le truc reste le même :
- Avoir une seule source de vérité
- Générer le reste à partir de celle-ci
Ici, nous traitons maintenant de :
- Types
- Schémas
- Spécifications d'API
La meilleure façon que j'ai trouvée pour les maintenir tous synchronisés est de partir des spécifications d'API. Je vous recommande d'utiliser la norme OpenAPI pour décrire à quoi ressemble votre API. En prime, vous pouvez utiliser des outils qui généreront une documentation interactive et esthétique comme Swagger.
Une fois que vous avez vos spécifications OpenAPI, vous pouvez utiliser https://github.com/drwpow/openapi-typescript pour générer des types TypeScript.
Maintenant que nous avons les spécifications d'API et les types, nous avons besoin d'un moyen de générer les schémas aussi. C'est là que https://github.com/fabien0102/ts-to-zod entre en jeu. Il générera des schémas Zod à partir des définitions de types TS, ce qui est pratique lorsque vous avez les types avant les schémas.
Investissez un peu de temps et vous devriez être en mesure de créer une seule commande qui régénérera vos types et schémas d'API chaque fois que vos spécifications OpenAPI seront mises à jour. Voilà 🎂
Ne saisissez pas ce que vous ne possédez pas
Lorsque vous n'avez pas le contrôle sur les données, il est plus sûr de les traiter comme étant de type unknown. Autrement, cela peut créer des angles morts dans votre application et vous causer de gros problèmes à l'avenir.
- Validez les données qui entrent dans votre système en temps d'exécution.
- Générez des types à partir des schémas de validation.
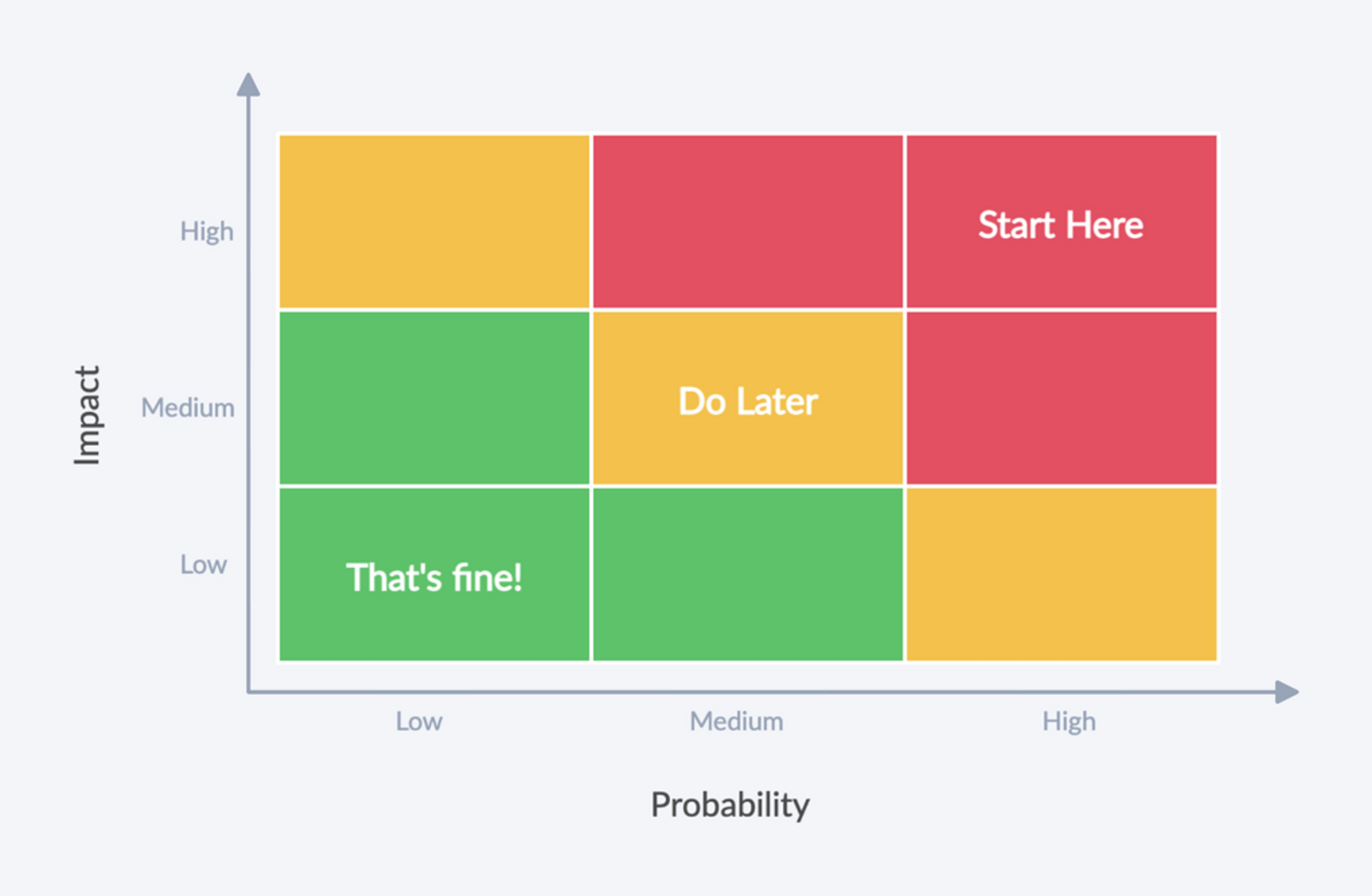
« Devrais-je le faire partout ? »
Ça dépend™. Probablement pas. C'est une question de gestion des risques.
À quel point avez-vous confiance en ces types ? Quelles seraient les conséquences si les choses tournent mal ? Avez-vous déjà des erreurs de type en production ?
Commencez par les parties les plus risquées de votre application. Faites des itérations.
« Aurai-je moins d'erreurs d'exécution? »
Oui !
Eh bien, vous pourriez voir plus d'erreurs au début. C'est ce qui se produit lorsque vous mettez en évidence un problème : il devient évident pour tout le monde. Lorsque vous intégrez une nouvelle API tierce, vous vous rendrez compte que certaines de vos attentes ne correspondent pas à la réalité. Je dirais que c'est un avantage !
Cela vous donnera l'opportunité de corriger les erreurs qui, autrement, auraient été ignorées jusqu'à très tard dans le processus.
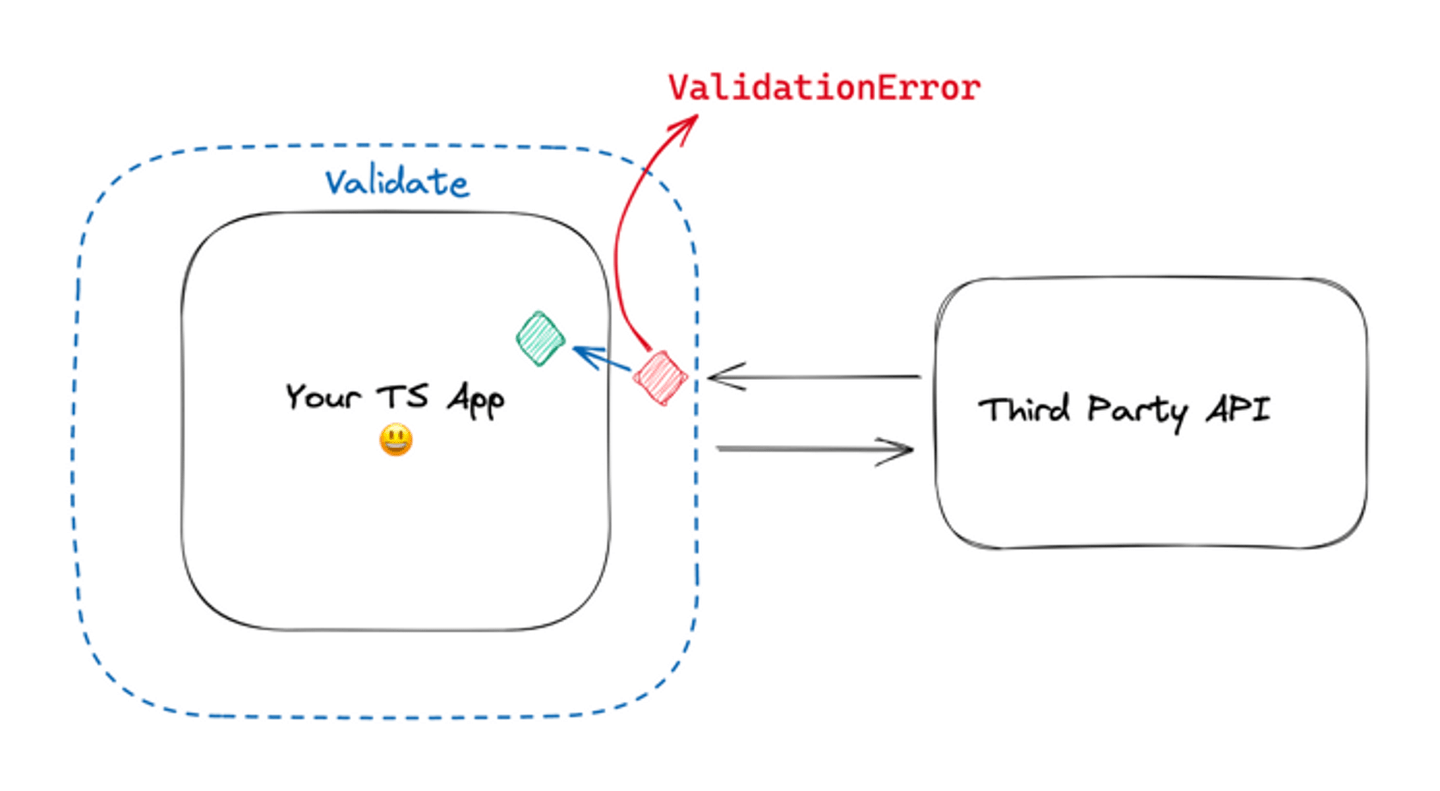
« Il y a cette autre équipe au travail qui casse notre application chaque fois qu'ils modifient l'API sans nous le dire...»
Vous êtes le client d'une API que vous ne possédez pas, même si la propriété est au sein de votre entreprise. C'est en fait un problème très classique. Les Context Maps de la conception orientée domaine peuvent vous aider à rendre ce problème visible pour tous.
Maintenant, devriez-vous faire confiance à l’API de l’autre équipe et mettre en place un schéma de validation ? Ça dépend™ 🌈
La validation des données en temps d'exécution a un coût. C'est plus de code à maintenir et plus de choses qui peuvent mal tourner. Lorsque vous n'avez pas le contrôle sur les données entrantes, cela en vaut la peine : Zod vous permet d’économiser du temps sur certains bugs que vous n'aurez pas à corriger.
Mais vous avez peut-être d'autres options !
Rappelez-vous ce que je vous ai dit si vous étiez responsable à la fois du client et du serveur : partagez les types entre eux. C'est moins de surcharge et vous obtiendrez les mêmes résultats.
Posez-vous donc ces questions :
- Pourraient-ils vous fournir un « typed SDK » qu'ils maintiennent ?
- Pourriez-vous partager les types avec cette autre équipe dont vous dépendez ?
- Si vous partagez les types mais qu'ils les cassent régulièrement, pourriez-vous introduire une sorte de versioning ? Pensez aux espaces de noms…
- Pourriez-vous mettre en place des tests de contrat entre vos équipes pour détecter toute incompatibilité avant qu'elle n'atteigne la production ?
Dans le pire des cas, vous traitez cette API comme ce en quoi vous ne pouvez pas avoir confiance et que vous ne possédez pas; donc validez les données en temps d'exécution.
Au moins, vous serez en mesure d'identifier la source du bug immédiatement (« L'équipe B a cassé notre application 5 fois ce trimestre »), et peut-être mettre en place une logique de secours pour protéger vos utilisateurs finaux.

Cet article vous a donné des idées ? Nous serions ravis de travailler avec vous ! Contactez-nous et découvrons ce que nous pouvons faire ensemble.




-min.jpg)

