Development
How to catch blind spots at the edge of your TypeScript app


You are coding in TypeScript. Everything is lovely typed and sweet. You said bye to JavaScript’s infamous undefined is not a function and have no regrets!
And yet, you can’t believe the error you have in front of you. It’s from your error monitoring system, and it comes from Production:
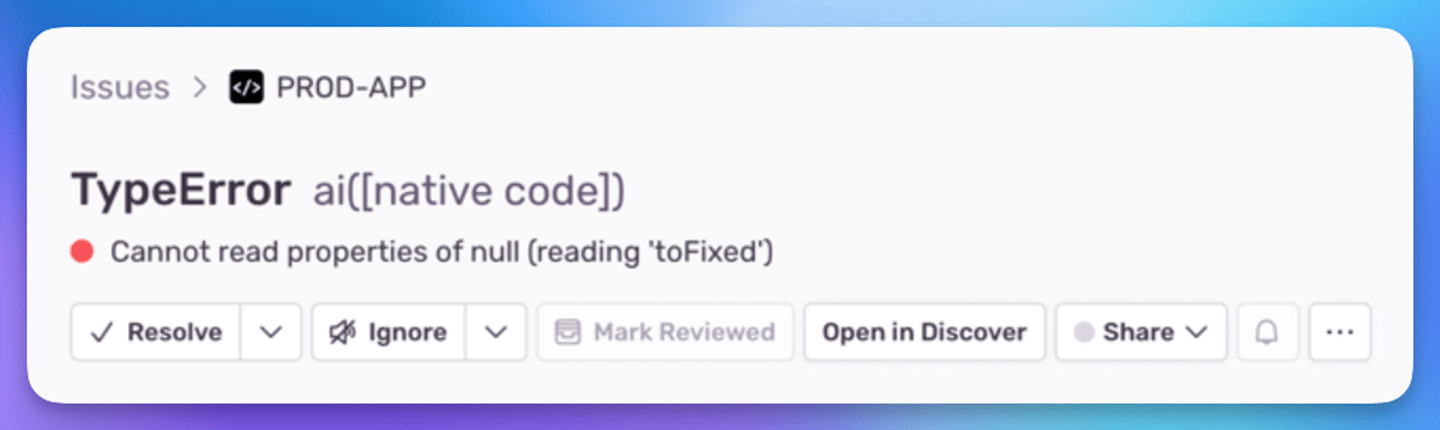
Wait… how is that possible?!
You think, as a legitimately confused TS developer. How did that type of error slip through? Did someone use any somewhere?
Well, no. At least, not directly. This is the good news.
The bad news is that you certainly have much, much more blind spots in your TypeScript application. And you just discovered one!

Stories like this are common. Sometimes, they can have terrible consequences for the product—like Mazda head units getting bricked because of a local NPR station in 2022 😅
These potential errors come from outside of your software. The external world you don’t control. They come in different shapes, but here I will focus on the 3 most common ones:
- Client inputs
- Third-party APIs responses
- Database fetches
Let’s see how to address these, and what they all have in common.
Blind spots everywhere
1. Client Inputs
“Client” refers to users or systems that are providing inputs to your system. It could be:
- An end-user of your front-end application
- Another application that consumes your backend API
- A developer who uses your CLI
If you are in control of different systems that communicate with each other (eg. client <> server), then you should find a way to share the types between your systems. tRPC is a great tool to build type-safe APIs and get that type-safety on the client side. It also uses the techniques I am about to present to you 😉
Now, go to the edge of the systems you own. Consider the places where external users will provide you with inputs at runtime.
You need to validate these inputs at runtime.
You may know the adage already:
Never trust user inputs.
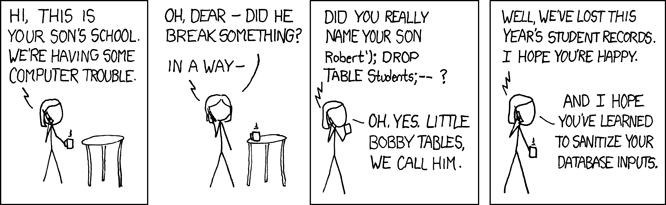
There is always a relevant XKCD: https://xkcd.com/327/
Regardless if the user is malicious, there is one thing you can be sure of: TypeScript can’t enforce the types on runtime data. You have to validate what’s coming into your system. It’s better to fail early if it doesn’t match the types you expect.
To be completely accurate, the type of user input is unknown. You wish it would be a string or follow some object interface. But you can’t enforce the client to do the right thing. Something has to verify the data at runtime, and TypeScript can’t do that.
2. Third-Party API responses
There are different levels of confidence when working with an external API:
🟢 They give you a typed SDK
🟡 They don’t have a typed SDK, but they have online documentation!
🟠 Well, they have some form of documentation in a .docx file
🔴 Wait, what docs? Oh, this one is out-of-date, sorry!
Third-party API documentation can easily be inaccurate, unless it’s generated from the source code—which is not common, in my experience. Yet, I’ve worked on TypeScript projects where the external API types were transcribed from the docs into .d.ts files.
Imagine coming across this asana.d.ts file that attempts to compensate for their like of TypeScript SDK:
// https://developers.asana.com/docs/taskexport interface AsanaTask { gid: string; resource_type: string; approval_status: 'pending' | 'approved' | 'rejected' | 'completed'; // …}
Well, that would be a lot of work and optimism.
In production, Asana may have an issue and resource_type may be missing from a response. Yet, all of our code expect this field to be present. And just like that, it crashes our expectations… and maybe our application at some point later. Back to JS land.
So, what can you do?
You need to validate Third-Party API responses at runtime.
Since you can’t have strong confidence Asana will behave as documented in all situations at runtime, you need to verify. Most of the time, it will behave as they said. But if they don’t, you will catch it right away and prevent this hiccup to propagate in your system.
3. Database fetches
This one may be less obvious. Databases are trustworthy. But are they?
Well, as everything sophisticated enough in life: It Depends™.
Here again, it’s a matter of confidence. And here is a handy checklist of questions to ask yourself to gauge what your confidence level should be:
- Are there enforced schemas for the stored data? Think SQL vs. NoSQL databases.
- Are the schemas connected to your type definitions? Duplicated truth may get out of sync.
- Can people change the data without using your application?
- Are there scripts that may update the data without using your application?
- Are there other applications that can update the data without using your application?
See, all of the types within your TypeScript backend can’t prevent some external actor from directly connecting to your database and messing up the data. If the protection of the type isn’t on the database level, you may not fetch the types you think you are fetching.
Properly built SQL databases are easier to trust than NoSQL documents that can store anything.
If you are using Firestore like me these days, be aware that any client has direct access to your “scalable NoSQL cloud database”. Optimistically typing what should come out of a subscription may lead to errors in production:
db .collection('ad-campaigns') .onSnapshot( (snapshot) => { const campaigns = snapshot.docs.map( // ❌ This may be false and you won't handle it! (d) => d.data() as Campaign[] ) setAdCampaigns(campaigns) } )
So what do you do when you can’t fully trust your database to not have been tampered?
You need to validate Database fetches at runtime.
I bet you start to understand the pattern here 😉
Now, let’s see how you can easily validate data at runtime…
Zod to the rescue!
Theoretically, validating data at runtime consists in:
- Declaring that data type as
unknown - Verifying the schema of the data and throwing if it’s not the one we expect
That way, TypeScript will ensure we don’t make expectations that we haven’t verified yet.
app.get("/price", (req, res) => { const code = req.query.code as unknown; // We can't use code as a string here, TS would complain… if (typeof code !== 'string') { return res.sendStatus(400) } // Now we KNOW code is a string})
We could do that and progressively build our collection of helpers that will reduce boilerplate… or we can use a library that has done this exact job for us!
There are a couple of data validation libraries out there such as Joi or Yup. But Zod is now quite popular and was built TypeScript-first.
Using zod to validate data has 2 steps:
- Define the schema
- Use it to parse the runtime data
app.get("/price", (req, res) => { const code = req.query.code as unknown; // We can't use code as a string here, TS would complain… if (typeof code !== 'string') { return res.sendStatus(400) } // Now we KNOW code is a string})
Zod API will allow you to declare schema in a way that’s very close to what declaring interfaces look like:
const userSchema = z.object({ username: z.string(), location: z.object({ latitude: z.number(), longitude: z.number(), }), strings: z.array(z.object({ value: z.string() })),});
Therefore, you can start defining the schema and using schema.safeParse(data) to validate what happens at runtime:
app.get("/users", (req, res) => { const result = userSchema.safeParse(req.query.user); // Fail early if (!result.success) { return res.status(400).json(toErrorResponse(result.error)) } const user = result.data // Now we KNOW user follows the schema…})
What about duplication?
You may have noticed that now you have duplicated the source of truth:
- In your existing
Usertype - In your new
userSchemadefinition

See, Zod figured it out for you: it can infer the type from the schemas. You don’t have to maintain types and schemas in parallel, the types are generated from the schemas:
type User = z.infer<typeof userSchema>// Now you can use this User type anywhere you need!
What about my API docs?
So you don’t want to be the Third-Party API with outdated documentation? Great!
The trick is always the same:
- Have a single source of truth
- Generate the rest from it
Here, we are now dealing with:
- Types
- Schemas
- API specs
The best way I have found to keep them all in sync is to start from the API specs. I recommend you use the OpenAPI standard for declaring what your API looks like. As a side bonus, you can use tools that will generate beautiful, interactive documentation like Swagger.
Once you have your OpenAPI specs, you can use https://github.com/drwpow/openapi-typescript to generate TypeScript types from them.
Now that we have API specs and Types, we need a way to generate the Schemas too. That’s where https://github.com/fabien0102/ts-to-zod comes into play. It will generate Zod schemas from TS type definitions—this is handy for when you got the types before the schemas.
Invest a little time and you should be able to craft a single command that will regenerate your API types & schemas whenever your OpenAPI specs are updated. Voilà 🎂
Don’t type what you don’t own
When you don’t have control over the data, it’s safer to treat it as unknown. Optimistic typing creates blind spots all over your application, and this may bite you hard down the road.
- Validate data entering your system at runtime.
- Generate types from the validation schemas.
“Should I do that everywhere?“
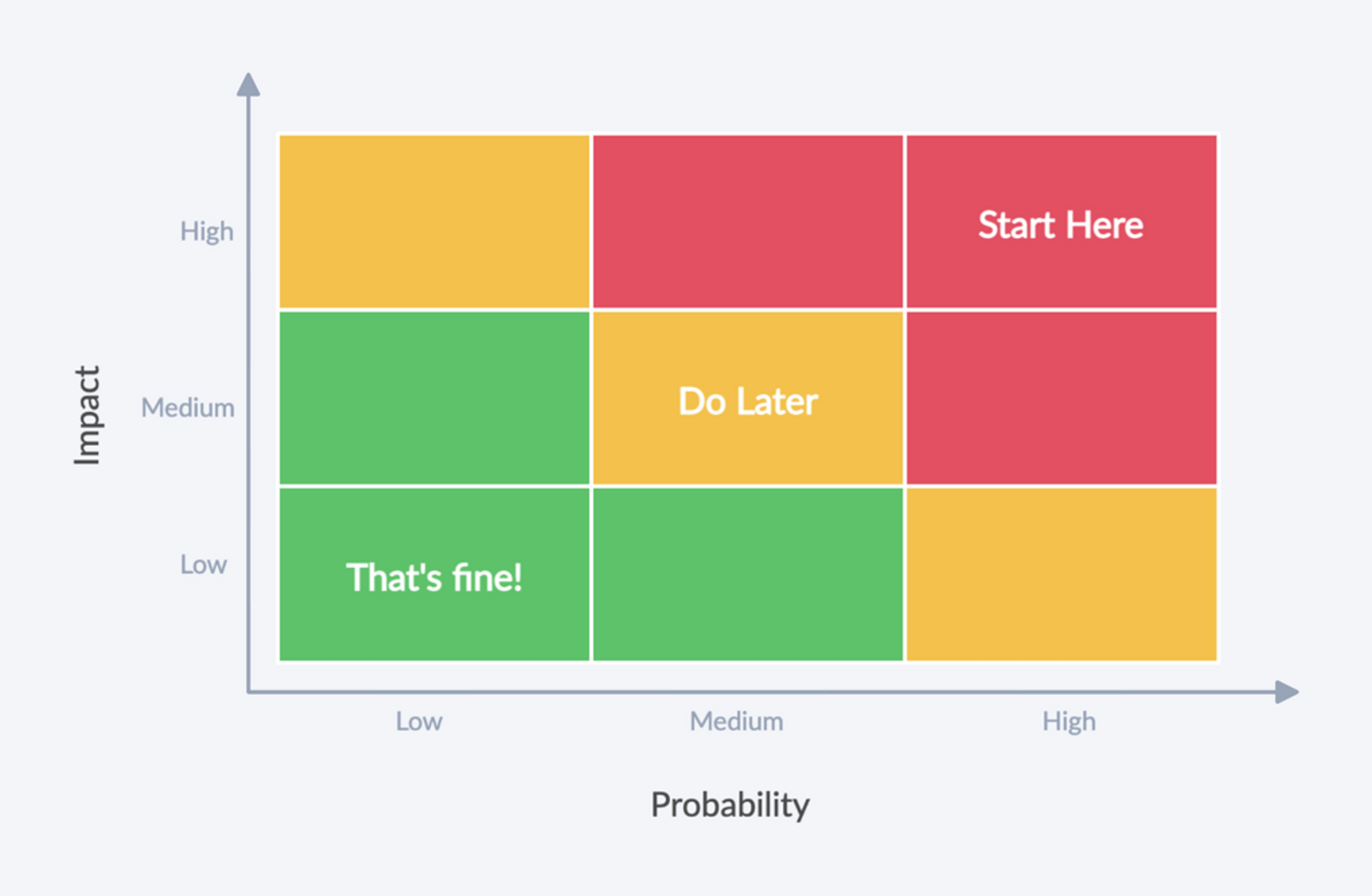
It Depends™. Probably not. It’s a question of risk management.
How confident are you about these types? What would be the impact if things go wrong? Do you already have type errors in production?
Start with the riskiest parts of your application. Iterate.
“Will I get fewer runtime errors?”
Yes!
Well, you may see more errors at first. That’s what happens when you highlight a problem: it becomes obvious to everyone. When integrating with a new third-party API, you will realize that some of your expectations don’t match the reality. I say that’s a benefit!
It will give you the opportunity to fix errors that would otherwise have been ignored until very late.
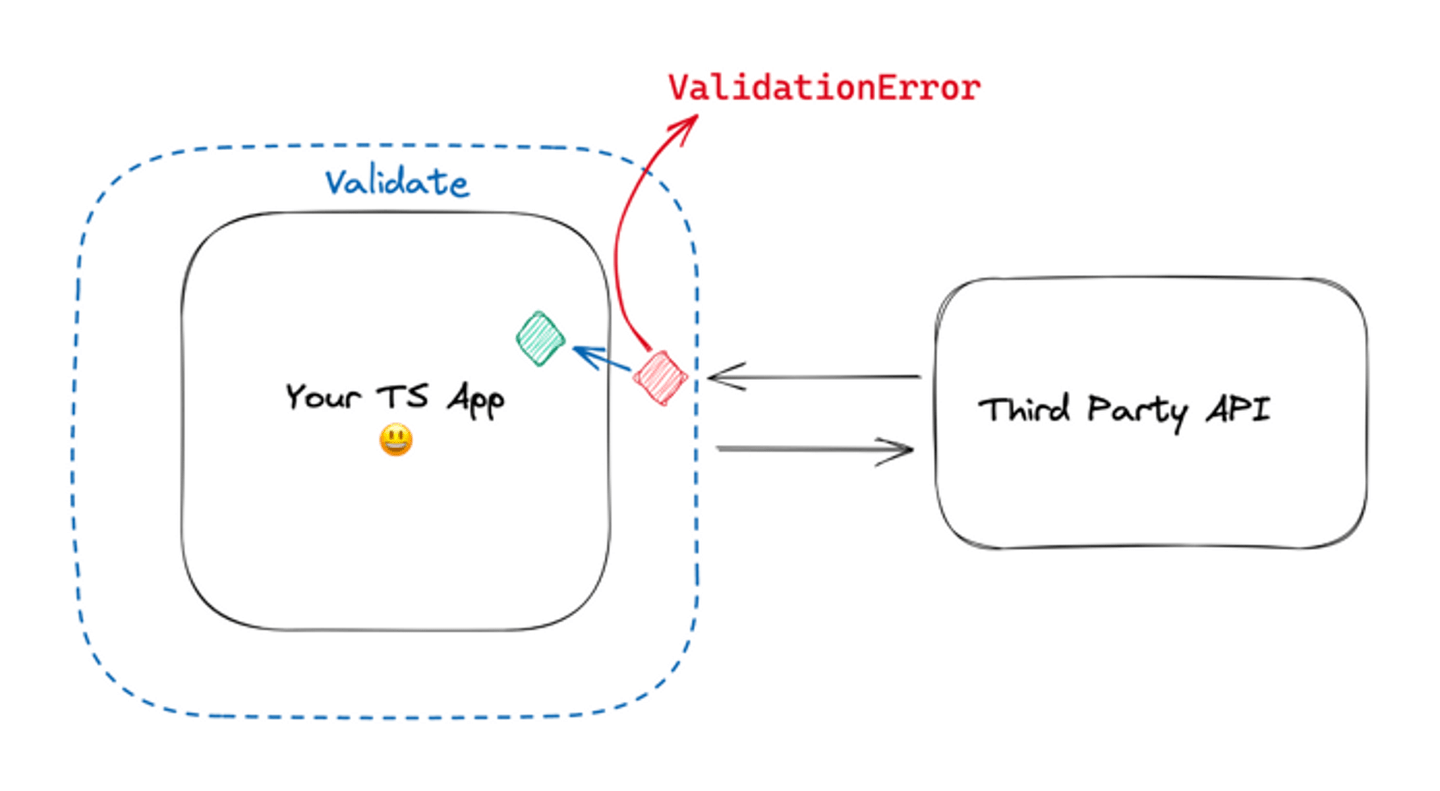
“There is this other team at work that keeps breaking our app when they change the API without telling us…”
You are the Client of an API you don’t own, even though the ownership is within your company. That’s actually a very classic problem. Domain-Driven Design Context Maps can help make this problem explicit.
Now, should you not trust the other team’s API and put validation schema? It Depends™ 🌈
Validating data at runtime has a cost. It’s more code to maintain, and more things that can go wrong. When you are not in control of the incoming data, it’s worth it: Zod keeps the barrier low and you save time in bugs you don’t have to fix.
But you may have other options!
Remember what I told you if you were in charge of both the Client and the Server? Share types between these. It’s less overhead and will give you the same results.
Thus, ask yourself these questions:
- Could they give you a typed SDK they maintain?
- Could you share types with the other team you depend on?
- If you share types but they keep breaking them, could you introduce some sort of versioning? Think about namespaces…
- Could you set up contract tests between your teams to raise any mismatch before it reaches production?
Worst-case scenario, you treat this API as something you can’t fully trust and you don’t own: validate data at runtime.
At least, you will be able to identify the source of the bug right away (”Team B broke our app 5 times this quarter”), and maybe put some fallback logic in place to protect your end-users.

Did this article start to give you some ideas? We’d love to work with you! Get in touch and let’s discover what we can do together.






