IA
Comprendre la détection d’activité vocale : comment le VAD alimente les systèmes vocaux en temps réel

Les assistants vocaux sont aujourd’hui devenus une façon intuitive et répandue pour les utilisateurs d’interagir avec des applications et des appareils. L’interaction par la voix se déploie rapidement afin de simplifier les flux de travail dans divers contextes, comme les cliniques médicales ou les laboratoires pharmaceutiques. En grande partie grâce à l’essor des performances de la reconnaissance vocale (Speech-to-Text) au cours des dernières années — incluant le désormais célèbre modèle Whisper d’OpenAI — le développement de systèmes d’interaction vocale est plus accessible que jamais. Pourtant, les défis liés à la mise en place de solutions vraiment précises et utiles demeurent bien réels.
Cet article est le premier d’une série qui mettra en lumière des aspects des systèmes d’interaction vocale souvent méconnus ou négligés, mais essentiels à leur succès.
Aujourd’hui, nous nous concentrons sur un composant crucial des systèmes vocaux modernes : la détection d’activité vocale (Voice Activity Detection ou VAD). Que ce soit pour donner une commande à un appareil intelligent ou pour transcrire une conversation en temps réel, la précision et la réactivité des systèmes vocaux dépendent largement d’un VAD performant. Nous verrons ce qu’est le VAD, son rôle dans les systèmes vocaux en temps réel, les approches utilisées pour le mettre en œuvre, et comment différentes méthodes peuvent être combinées afin d’atteindre une performance optimale selon le contexte.
Points clés à retenir
La détection d’activité vocale (VAD) est le mécanisme crucial qui rend les systèmes vocaux en temps réel pratiques et fiables. En identifiant où commence et où se termine la parole dans un flux audio continu, le VAD s’assure que seuls les segments pertinents sont envoyés aux modèles de transcription. Cela réduit le gaspillage de ressources informatiques et garde les interactions fluides.
- Pourquoi c’est important: sans VAD, chaque son (voitures qui passent, bruit de fond) serait traité comme une parole potentielle. Résultat : charge de calcul inutile, augmentation de la latence et dégradation de l’expérience utilisateur. Le VAD résout ce problème en filtrant l’audio non pertinent avant qu’il n’atteigne le modèle de reconnaissance vocale.
- Comment ça fonctionne: deux grandes stratégies sont utilisées. Les modèles probabilistes s’appuient sur l’apprentissage machine pour reconnaître des motifs subtils de la parole, offrant une grande précision mais parfois des résultats instables. Les méthodes basées sur l’énergie, quant à elles, sont simples et efficaces, mais peuvent confondre bruit et parole.
- Le meilleur des deux mondes: en pratique, les systèmes hybrides combinent ces approches. Les modèles probabilistes permettent une détection fine, tandis que les seuils d’énergie ajoutent stabilité et contrôle. Ensemble, ils offrent des délimitations plus fluides, moins d’erreurs et une utilisation plus efficace des ressources.
Qu’est-ce que la détection d’activité vocale (VAD) et pourquoi est-ce essentiel?

Essentiellement, le VAD consiste à déterminer automatiquement si un segment audio contient de la parole humaine ou simplement du bruit de fond. Bien que cela puisse sembler trivial, cette fonction est indispensable pour assurer le bon fonctionnement des assistants vocaux en temps réel.
La plupart des modèles de reconnaissance vocale ouverts qui ont propulsé l’essor des systèmes d’interaction vocale ont un fonctionnement simple : un fichier audio en entrée, une transcription en sortie. Cela signifie qu’un flux audio continu provenant d’un micro ne peut pas être traité directement par le modèle sans découpage préalable. C’est là que le VAD intervient : il décide quels segments doivent être extraits du flux audio du micro, et où ces segments doivent commencer et se terminer.
Un autre objectif tout aussi important, surtout pour les systèmes temps réel qui fonctionnent localement : éviter de gaspiller temps et ressources informatiques à transcrire de l’audio non pertinent. En d’autres mots, s’assurer que seuls les segments significatifs sont traités.
Le VAD est particulièrement critique dans les systèmes de commandes vocales en temps réel, où :
- L’entrée audio est un flux continu.
- Le système doit identifier avec précision le début et la fin de la parole.
- Les délais et la surcharge de calcul doivent être réduits au minimum pour assurer la réactivité.
Approches du VAD
Imaginons un micro qui capte en continu l’audio de notre environnement, pendant que le système tente de détecter les commandes vocales de l’utilisateur avec un modèle de reconnaissance vocale. Sans un VAD robuste, le modèle transcrirait absolument tout ce qu’il entend — du bruit ambiant aux clics de clavier. Résultat : gaspillage de ressources de calcul, délais, et perte de précision dans la transcription en temps réel. D’où la nécessité d’un VAD performant.
De façon générale, on peut classer le VAD en deux types :
1. VAD probabiliste
Il utilise des modèles de réseaux de neurones avancés, entraînés à distinguer les segments de parole des segments de non-parole. Les caractéristiques du signal audio sont d’abord extraites, par exemple à l’aide de la transformée de Fourier à court terme (STFT). Elles sont ensuite traitées par un modèle de classification neuronale (p. ex. LSTM, attention multi-têtes, CNN).
Avantages:
- Classification très précise et granulaire.
- Capacité d’adaptation à des conditions acoustiques variées.
Inconvénients:
- Risque d’erreurs sur certaines subtilités de la parole.
- Probabilités parfois instables, nécessitant un réglage minutieux des seuils.
2. VAD basé sur l’énergie
Ces systèmes utilisent les niveaux d’énergie (amplitude moyenne absolue) du signal audio pour détecter la présence de parole. Une règle simple pourrait être : « Si l’énergie de la dernière seconde tombe sous un certain seuil, le segment audio prend fin. »
Avantages:
- Facile à implanter.
- Très peu coûteux en calcul.
Inconvénients:
- Bruit et parole difficiles à distinguer quand leurs niveaux d’énergie sont similaires.
- Propension aux faux positifs dans des environnements bruyants.
Les systèmes hybrides : le meilleur des deux mondes?
Les solutions d’apprentissage automatique appliqué adoptent souvent des approches hybrides afin de maximiser la fiabilité et la performance. Bien que l’apprentissage automatique offre une plus grande précision et une meilleure capacité de généralisation, il est souvent considéré comme une « boîte noire » et peut manquer du contrôle fin et de l’explicabilité que permettent des approches plus classiques. Cela s’applique aussi aux systèmes vocaux et au VAD (Voice Activity Detection).
Les approches hybrides conviennent particulièrement aux cas d’usage concrets, où le contexte d’utilisation du système est bien connu, permettant ainsi de combiner plusieurs méthodes de façon spécifique afin de tirer parti des avantages de chacune.
Comment un VAD basé uniquement sur la probabilité peut-il échouer dans certains cas?
La probabilité de parole, bien que précise, peut être instable et pas toujours idéale pour de longs segments audio (par exemple, des phrases complètes). Sans logique de vérification supplémentaire, une phrase pourrait être coupée en deux si l’utilisateur hésite. De plus, certains utilisateurs allongent le début ou la fin de leurs mots, ce qui peut amener le modèle de reconnaissance de la parole à confondre parole et bruit. Les méthodes basées sur l’énergie présentent l’avantage de considérer les variations d’énergie sur des périodes de temps, offrant ainsi plus de stabilité et de contrôle.
Dans notre cas, une approche hybride pratique du VAD, fondée sur les méthodes de probabilité et d’énergie décrites ci-dessus, pourrait fonctionner ainsi :
- Détermination du début de la fenêtre: utilisation d’un modèle basé sur la probabilité (par ex. Silero VAD) avec un seuil défini (ex. 70 %) pour détecter le début de la parole. Si l’audio dépasse ce seuil de probabilité de voix de manière continue pendant une durée donnée (ex. 400 ms), la parole est considérée comme commencée.
- Détermination de la fin de la fenêtre: combinaison de deux vérifications:
- La probabilité de voix reste en dessous d’un certain seuil (ex. inférieur à 50 %) pendant une durée spécifiée (ex. 500 ms).
- Les niveaux d’énergie chutent de façon significative (ex. en dessous de 80 % de l’énergie moyenne de la dernière seconde).
- La probabilité de voix reste en dessous d’un certain seuil (ex. inférieur à 50 %) pendant une durée spécifiée (ex. 500 ms).
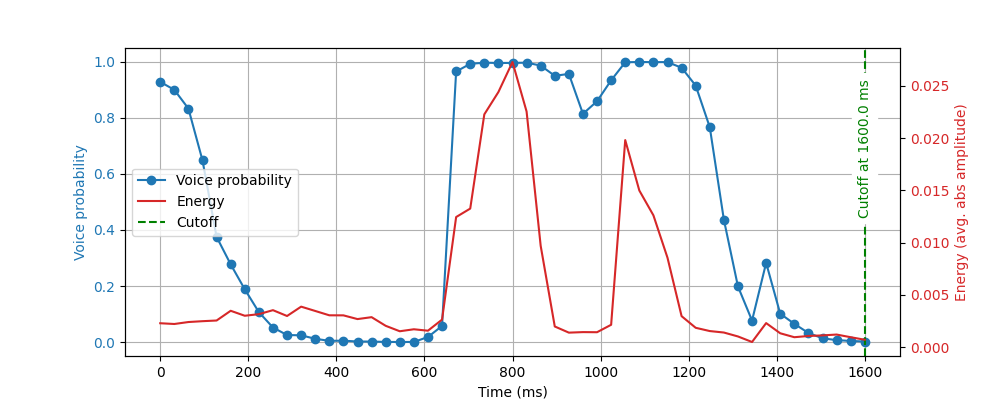
La meilleure façon de combiner ces méthodes est, bien sûr, de les tester individuellement afin de comprendre où chacune manque de précision pour notre cas d’usage et d’identifier les domaines où elles peuvent se compléter. Comme c’est le cas en apprentissage automatique appliqué en général, les tests qualitatifs et quantitatifs ont chacun leur utilité. Obtenir des métriques de précision sur votre jeu de test vous aidera à savoir dans quelle mesure votre approche hybride a amélioré les performances et quels cas spécifiques représentent le plus d’échecs. Les tests qualitatifs, quant à eux, permettent de mieux comprendre ce qui fonctionne et ce qui ne fonctionne pas. Cela conduit naturellement à découvrir les cas limites les plus pertinents pour votre contexte d’utilisation.
En résumé
La détection d’activité vocale est une technologie essentielle, souvent invisible, qui améliore considérablement la performance et la fiabilité des applications modernes basées sur la voix. En différenciant intelligemment la parole du bruit de fond, un système VAD robuste offre des bénéfices concrets :
- Performance en temps réel améliorée : réduit significativement la latence, permettant des commandes vocales en temps réel sans délais frustrants.
- Efficacité des ressources : évite les calculs inutiles, réduit la charge du processeur et préserve la batterie des appareils.
- Précision accrue des transcriptions : garantit que la transcription et la reconnaissance des commandes se concentrent uniquement sur l’audio pertinent, minimisant les erreurs liées au bruit.
Tous ces aspects contribuent à offrir une expérience d’interaction vocale bien meilleure pour les utilisateurs, ce qui doit toujours rester l’objectif principal d’un système vocal. À mesure que la technologie vocale continue d’évoluer et de se généraliser, le VAD évoluera également, permettant des solutions vocales plus intelligentes, rapides et précises à l’avenir.
Cet article fait partie de notre série sur les systèmes d’interaction vocale, où nous partageons des enseignements tirés de projets réels. Si vous explorez l’intégration de technologies vocales avancées dans vos applications, notre équipe peut vous aider à développer des solutions à la fois pratiques et innovantes. Discutons de votre projet.


Cet article vous a donné des idées ? Nous serions ravis de travailler avec vous ! Contactez-nous et découvrons ce que nous pouvons faire ensemble.


.png)
-min.jpg)

