AI
Understanding Voice Activity Detection: How VAD Powers Real-time Voice Systems

Voice assistants today have become a standard, intuitive way for users to interact with applications and devices. Interaction through voice is rapidly spreading to help streamline workflows in a variety of settings, such as in medical clinics or pharmaceutical labs. Due in large part to the boom seen in Speech-to-Text performance in recent years, including OpenAI's now famous Whisper model, Voice Interaction system development is more accessible than ever. And yet, the hurdles of implementing truly accurate and useful Voice Interaction are very real.
This article is the first of a series focusing on aspects of Voice Interaction systems that are often little known or overlooked, but that need to be addressed in order for it to be successful.
Today's article focuses on a crucial component of modern Voice systems: Voice Activity Detection (VAD). Whether it's issuing a command to a smart device or transcribing real-time conversations, the accuracy and responsiveness of voice systems hinge significantly on a well-performing VAD. We'll explore what VAD is, its role in real-time voice systems, the approaches used to implement it. We’ll also look at how a system might blend various methods to achieve optimal performance for your context.
Key Takeaways
Voice Activity Detection (VAD) is the crucial mechanism that makes real-time voice systems practical and reliable. By identifying where speech begins and ends in a continuous audio stream, VAD ensures that only relevant segments are passed to transcription models. This reduces computing resources waste and keeps interactions responsive.
- Why it matters: Without VAD, every sound (cars passing by, background chatter) would be treated as potential speech. This creates unnecessary computational load, increases latency, and degrades user experience. VAD solves this by filtering out irrelevant audio before it reaches the Speech-to-Text model.
- How it works: Two main strategies are commonly used. Probability-based models leverage machine learning to recognize subtle patterns in speech, offering high precision but sometimes unstable results. Energy-based methods, in contrast, are simple and efficient but prone to mistaking noise for speech.
The best of both worlds: In practice, hybrid systems can combine these approaches. Probability-based models provide fine-grained detection of speech, while energy thresholds add stability and control. Together, they deliver smoother boundaries, fewer mistakes, and more efficient resource usage.
What is Voice Activity Detection (VAD) and why does it matter?

At its core, Voice Activity Detection is the process of automatically determining if a given audio chunk contains human speech or is simply background noise. While this might seem trivial, this function is crucial to ensure the proper functioning of real-time Voice Interaction assistants. With the advent of Speech-to-Text models as a core component of such systems, VAD is a critical component that should not be overlooked.
Most of the open Speech-to-Text models that have fuelled the boom in voice interaction systems have a very well defined input and output: they provide the transcription (text) as an output for a given audio chunk (or file) in input. This means that the continuous audio stream for the microphone cannot be provided as-in, in a plug-and-play manner to the Speech-to-Text model without prior chunking. This is where VAD comes into play: to decide which audio chunk we should extract from the microphone’s stream, and where it should start and end.
Additionally, there is also another goal, no less important for real-time voice systems, especially those that run locally: avoid wasting time and computational resources transcribing irrelevant audio. Or, in other words, ensuring that only meaningful audio is processed further.
VAD is particularly critical in real-time voice command systems, where:
- The audio input is a continuous stream.
- The system must identify the beginning and end of speech accurately.
- Delays and computational overhead need to be minimized for responsiveness.
Approaches to VAD
Imagine a microphone continuously streaming audio data from our environment, and our system attempting to detect voice commands from the user with a Speech-to-Text model. Without a robust VAD, the model would transcribe everything it hears, from loud ambient noises to light keyboard clicks. This scenario not only wastes computing resources but also leads to delays and reduced accuracy in real-time transcription. This highlights the need for a robust voice activity detection component in our system.
Generally, VAD can be categorized into two types:
1. Probability-Based VAD
Probability-based VAD uses advanced neural network models trained to distinguish between speech and non-speech audio segments. The audio signal's features will first be extracted, employing for example methods such as Short-Time Fourier Transforms (STFT) to obtain features from the frequency space. The audio input features will then be processed through a neural classification model, with an architecture like Long Short-Term Memory (LSTM), Multi-head Attention, or Convolutional Neural Networks (CNN).
Pros:
- Highly precise classification at a granular level.
- Adaptable to varied acoustic conditions.
Cons:
- Can occasionally misclassify certain speech nuances.
- Probabilities may vary widely, requiring careful threshold tuning.
2. Energy-Based VAD
Energy-based VAD systems use the energy levels (absolute average amplitude) of audio signals to detect speech presence. A simple rule might be: "If the energy level in the past second falls below a threshold, the current audio chunk ends."
Pros:
- Easy to implement.
- Minimal computational overhead.
Cons:
- Noise and speech are indistinguishable at similar energy levels.
- Prone to false positives in noisy environments.
Hybrid VAD Systems: Best of Both Worlds?
Applied Machine Learning solutions often adopt hybrid approaches to maximize reliability and performance. While Machine Learning offers greater accuracy and generalization, it is often considered to be black box and might lack the fine control and explainability of more classical approaches. This also applies to Voice systems and VAD. Hybrid approaches are well suited for concrete use cases, where we know very well the context where our system will be used and thus can combine several methods in specific ways to get the best of each.
How might probability-based VAD fail in specific cases? Speech probability, while precise, can be volatile and not always best suited for long audio chunks (e.g. full sentences). Without some further checking logic, we might cut a sentence in half if the user hesitates. Or else, some users might trail the beginning or end of their words, and the speech model might mistake speech for noise. Energy-based methods have the advantage of considering energy changes over periods of time, thus providing more stability and control.
In our case, a practical hybrid approach to VAD based on the above energy and probability methods might look like this:
- Window Start Determination: Uses a probability-based model (e.g., Silero VAD) with a defined threshold (e.g., 70%) to detect the start of speech. If audio exceeds the voice probability threshold continuously for a defined duration (e.g., 400 ms), speech is considered to have started.
- Window End Determination: Combines two checks:
- Voice probability remains below a certain threshold (e.g., below 50%) for a specified time (e.g., 500 ms).
- Energy levels fall significantly (e.g., below 80% of the average energy for the past second).
- Voice probability remains below a certain threshold (e.g., below 50%) for a specified time (e.g., 500 ms).
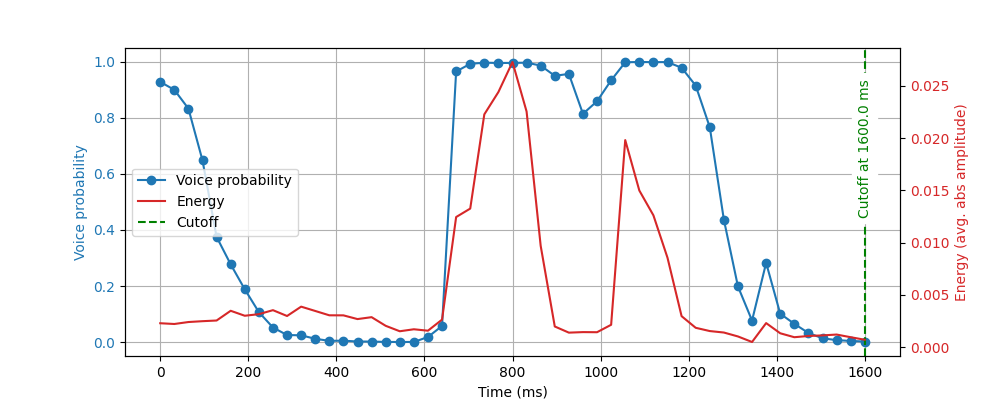
The best way to combine methods is of course to test them individually to understand where each one lacks accuracy for our use case and find areas where they can be complementary. As is the case for applied Machine Learning in general, both qualitative and quantitative testing serve their purpose. Obtaining accuracy metrics on your test set will help you know how much you improved with your hybrid approach and which specific cases account for the most failures. Qualitative testing on the other hand will allow you to gain better intuition of what works and what doesn't. This will lead you to naturally discover the edge cases that are the most relevant to your usage context.
Wrapping It Up
Voice Activity Detection is an essential, behind-the-scenes technology that significantly enhances the performance and reliability of modern voice-driven applications. By intelligently differentiating speech from background noise, a robust VAD system yields tangible benefits:
- Enhanced Real-time Performance: Reduces latency significantly, enabling real-time voice commands without frustrating delays.
- Resource Efficiency: Prevents unnecessary model computations, reducing CPU load, and conserving device battery.
- Improved Transcription Accuracy: Ensures transcription and command recognition focus exclusively on meaningful audio inputs, minimizing noise-induced errors.
All these aspects will result in a much better voice interaction experience for the users, which should always be the end goal of a voice system. As voice technology continues its evolution and adoption, so will VAD, driving smarter, faster, and more accurate voice-enabled solutions in the future.
This article is part of our series on voice interaction systems, where we share insights from real-world projects. If you’re exploring how to integrate advanced voice technologies into your applications, our team can help you build solutions that are both practical and innovative. Let’s talk.


Did this article start to give you some ideas? We’d love to work with you! Get in touch and let’s discover what we can do together.
-min.jpg)

.png)



