IA
L’apprentissage automatique prédictif au service des entreprises : ROI, précision et mise en production
-min.jpg)
La plupart des entreprises possèdent des données. Peu savent réellement les transformer en décisions. Selon McKinsey, seulement la moitié des chefs de la donnée et de l’analytique estiment être en mesure de stimuler l’innovation à partir des données, malgré des investissements massifs en analytique et en IA.
Pourquoi un tel écart ? Parce que regarder vers l’arrière pour expliquer ce qui s’est passé ne suffit plus. Le véritable défi consiste à anticiper ce qui va se produire.
Comparé à des disciplines plus spectaculaires comme la vision par ordinateur (Computer Vision) ou le traitement automatique des langues (NLP), l’apprentissage automatique prédictif peut sembler trompeusement simple. Après tout, les données sont déjà structurées en lignes et en colonnes. Mais cette simplicité est une illusion.
Alors que la vision par ordinateur et le NLP bénéficient de vastes jeux de données publics et du transfert d’apprentissage — on peut utiliser un modèle entraîné sur l’ensemble d’Internet pour reconnaître un chat —, l’IA prédictive repose presque exclusivement sur des données propriétaires. Il est impossible de télécharger un modèle pré-entraîné pour l’historique de ventes ou le taux de désabonnement propre à votre entreprise. Dans ce contexte, la connaissance du domaine devient un facteur de succès bien plus déterminant que la puissance de calcul.
Dans cet article, nous présentons les principes directeurs pour naviguer dans cette complexité. Nous abordons la définition du périmètre d’un projet, la préparation des données et la mise en production, tout en soulignant le rôle crucial de la communication avec les parties prenantes. Enfin, nous proposons une liste de vérification de préparation des données afin de s’assurer que les fondations sont solides.
Mais d’abord, clarifions une confusion fréquente.
Qu’est-ce que l’apprentissage automatique prédictif, au juste ?
L’apprentissage automatique prédictif est souvent présenté comme une « baguette magique ». En pratique, il se divise toutefois en deux approches aux règles très différentes. Bien qu’on les confonde souvent, l’analytique prédictive (ou apprentissage automatique tabulaire) et la prévision (forecasting) représentent deux façons fondamentalement distinctes de modéliser la réalité.
Apprentissage automatique tabulaire (Predictive Analytics)
Voyez l’apprentissage tabulaire comme une photographie. Il traite les données comme une coupe instantanée de la réalité, figée dans le temps, où chaque observation est supposée indépendante. Autrement dit, le comportement du client A n’influence pas directement celui du client B.
Cette approche est particulièrement adaptée aux décisions ponctuelles, lorsque l’objectif est de classer, de scorer ou de catégoriser des entités. On utilise des outils comme XGBoost ou la régression logistique pour répondre à des questions immédiates, formulées sous forme de problèmes de régression ou de classification.
Exemples
- Transactions frauduleuses
- Évaluation du risque de crédit
- Maintenance prédictive
- Désabonnement client
Exemple de données
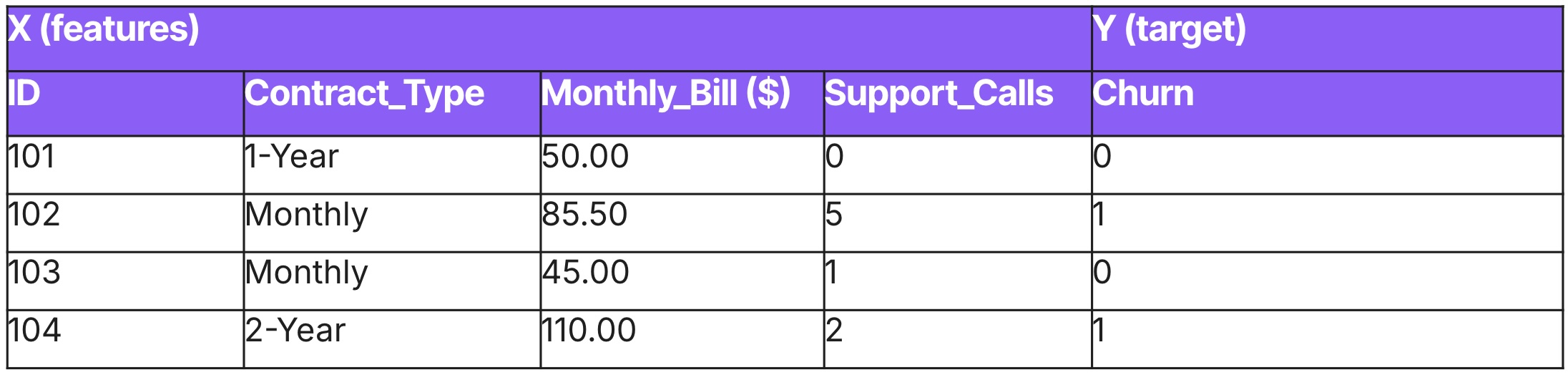
Prévision
La prévision s’appuie sur des données longitudinales pour répondre à des questions portant sur l’avenir. Elle rompt avec l’hypothèse d’indépendance et repose plutôt sur l’autocorrélation : ce qui s’est produit hier influence directement ce qui se produit aujourd’hui.
Cette approche est mieux adaptée aux décisions de planification et de capacité, lorsque l’objectif est d’estimer des volumes futurs dans le temps. Le but est de prolonger les tendances historiques afin d’estimer des quantités, par exemple les ventes totales du prochain trimestre. Comme cela exige une compréhension de la séquence et de la saisonnalité, on privilégie des architectures spécialisées en séries temporelles, comme les LSTM, ou des modèles de fondation tels que Chronos.
Exemples
- Prévisions mensuelles des ventes
- Demande hebdomadaire par UGS (SKU)
- Charge énergétique
Exemple de données
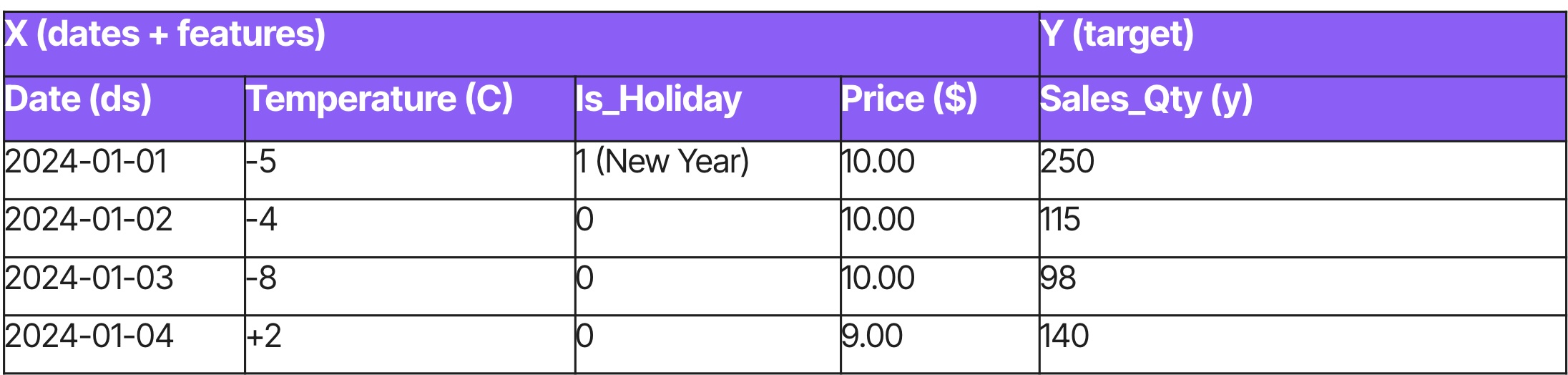
Comment l’aborder : un cadre de livraison
Voici les principes techniques et stratégiques nécessaires à la réussite d’un projet de modélisation prédictive.
Définition du projet
- Délimitation du périmètre: Pour éviter le glissement de portée, il faut ancrer le projet dans une définition réaliste de ce qui est « suffisant ». Les parties prenantes s’attendent souvent à des prédictions quasi parfaites. Il revient aux équipes techniques de définir un critère de succès lié au retour sur investissement plutôt qu’à la simple précision. Si un modèle naïf atteint 50 %, un modèle à 60 % peut être très rentable s’il améliore les résultats d’affaires.
- Définition d’un point de référence: Cela établit une base de comparaison. Si un modèle XGBoost complexe ne surpasse qu’à peine une moyenne historique, il est rarement justifié de le déployer.
Préparation des données
- Intégrité des données: La priorité absolue est d’éviter le « voyage dans le temps » : entraîner un modèle avec des données générées après le moment de la prédiction. Cela crée une illusion de performance qui disparaît en production. Si un processus d’affaires comporte un délai de trois mois entre la prédiction et le résultat, l’entraînement doit refléter cette réalité.
- Continuité temporelle: Contrairement aux modèles tabulaires, les modèles de prévision exigent une chronologie strictement continue. Les dates manquantes doivent être insérées et imputées (souvent à zéro). Attention : lorsque les zéros dominent, on entre dans le régime des séries intermittentes, où le signal est facilement noyé par le bruit.
- Mises à jour destructives: Méfiez-vous des bases de données qui écrasent l’historique avec des valeurs corrigées. Entraîner un modèle sur ces données introduit un biais impossible à reproduire en temps réel.
- Qualité avant quantité: Un petit jeu de données propre et informatif surpassera presque toujours un vaste ensemble bruité.
Modélisation et évaluation
- Complexité des modèles: La complexité est une forme de dette technique. Des modèles simples, qui atteignent 90 % de la performance d’un réseau neuronal profond, sont souvent préférables : ils sont plus robustes et plus faciles à maintenir.
- Mesures d’évaluation: Optimiser uniquement la précision est une erreur fréquente. Elle masque les coûts réels des faux positifs et faux négatifs. Les courbes de profit sont souvent plus pertinentes. Pour les données intermittentes, évitez le MAPE, mathématiquement instable, et privilégiez le MASE ou le RMSE.
- Interprétabilité: L’explicabilité doit être considérée comme une fonctionnalité essentielle. Un modèle légèrement moins précis mais compréhensible est souvent préférable à une boîte noire.
- Validation croisée: Évitez le biais de regard vers l’avenir. Les divisions aléatoires sont inadaptées aux données temporelles. Utilisez toujours une séparation chronologique.
Déploiement et suivi
- Dérive des données: Dès qu’un modèle est déployé, il commence à se dégrader. Surveillez la distribution des données d’entrée. Un changement soudain est un signal d’alerte précoce.
- Boucle de rétroaction:Si un modèle empêche certaines actions, il peut créer des angles morts. Maintenez toujours un groupe de contrôle pour mesurer le gain réel.
- Démarrage à froid: Prévoyez une stratégie de repli pour les nouveaux clients ou produits sans historique.
Compétences relationnelles et gestion des parties prenantes
- Gestion des attentes: L’IA est expérimentale par nature. Évitez les promesses irréalistes et structurez les engagements autour de phases d’exploration.
- Communication: Traduisez les métriques techniques en impact d’affaires.
- Documentation: Documentez les décisions stratégiques, pas seulement le code.
Liste de vérification – préparation des données
Avant d’aller de l’avant, assurez-vous que ces conditions sont remplies. Sinon, le projet devrait être redéfini ou reporté.
A. Disponibilité des données
- Existence de la variable cible : disposons-nous d’étiquettes historiques ?
- Profondeur de l’historique : avons-nous suffisamment d’historique pour couvrir la saisonnalité ? (Un minimum de 12 mois est la norme en commerce de détail et en finance).
- Vérification des décalages (lag) : pouvons-nous accéder aux données d’entrée au moment de la prédiction ? (Par exemple, si la prédiction est faite à 9 h, les données de 8 h sont-elles réellement dans l’entrepôt de données, ou sont-elles chargées le jour suivant.
B. Qualité des données
- Vérification de la continuité : la chronologie est-elle strictement continue ? S’il y a des trous, avons-nous une stratégie pour les imputer (p. ex. remplissage par 0) sans détruire le signal ?
- Audit de fuite de données : avons-nous supprimé toutes les variables générées après l’événement ?Vérification des biais : les données historiques sont-elles biaisées ?
C. Implémentation et déploiement
- Exigence de latence : la prédiction doit-elle être en temps réel (<200 ms) ou en batch (de nuit) ? Le temps réel augmente les coûts d’ingénierie par un facteur de 10.
- Stratégie de démarrage à froid : disposons-nous d’une règle de repli pour les nouveaux utilisateurs/produits sans historique ?
- Ressources de calcul : quel est l’environnement d’entraînement et d’inférence (cloud/sur site) ?
Conclusion
L’apprentissage automatique prédictif ne consiste pas à construire des modèles parfaits. Il s’agit de prendre de meilleures décisions dans un contexte d’incertitude. Les projets les plus solides misent moins sur les algorithmes que sur l’intégrité des données, la stratégie d’évaluation et la réalité opérationnelle. Lorsqu’ils sont conçus avec des objectifs d’affaires clairs, des points de référence réalistes et un suivi rigoureux, les systèmes prédictifs deviennent des actifs durables plutôt que des expériences fragiles. En pratique, la simplicité, la transparence et la discipline surpassent presque toujours la complexité.


Cet article vous a donné des idées ? Nous serions ravis de travailler avec vous ! Contactez-nous et découvrons ce que nous pouvons faire ensemble.


.png)
-min.jpg)

