AI
Predictive Machine Learning for Business: ROI, Accuracy, and Deployment
-min.jpg)
Most companies have data. Few know how to turn it into decisions. According to McKinsey, only half of chief data and analytics officers feel they are able to drive innovation using data, despite massive investments in analytics and AI.
Why the disconnect? Because looking backward to explain what happened is no longer enough. The real challenge is anticipating what will happen next.
Compared to flashier disciplines like Computer Vision or Natural Language Processing (NLP), predictive machine learning can seem deceptively simple. After all, the data is already structured in rows and columns. But this simplicity is an illusion.
While CV and NLP benefit from massive public datasets and transfer learning—you can use a model trained on the entire internet to recognize a cat—predictive ML relies almost exclusively on proprietary data. You cannot download a pre-trained model for your company’s specific sales history or customer churn. This makes domain knowledge, rather than raw compute power, the defining factor for success.
In this post, we outline the guiding principles to navigate this complexity. We will cover how to scope a project effectively, manage data preparation, and handle deployment, while emphasizing the critical role of stakeholder communication. Finally, we provide a "Data Readiness Checklist" to ensure your foundation is solid.
But first, we must clear up a common confusion.
What is predictive ML anyway?
Predictive machine learning is often discussed as a monolithic "magic wand," but in practice, it splits into two approaches with very different rules. While often used interchangeably, Predictive Analytics (or Tabular ML) and Forecasting represent two fundamentally different ways of looking at reality.
Tabular Machine Learning
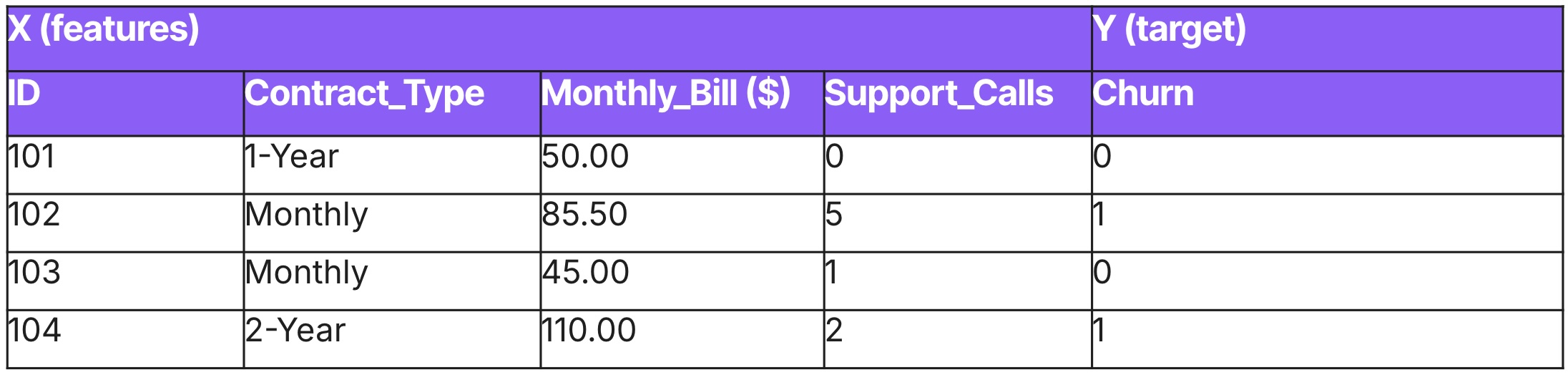
Think of Tabular ML as looking at a photo. It treats data as a static cross-section of reality frozen in time, where we assume that every data point is independent, meaning that the attributes of one observation do not inherently influence the probability of the next. We assume that Customer A’s behavior doesn't necessarily force Customer B’s behavior.
This approach is best suited for point-in-time decisions where the objective is to rank, score, or classify entities. We use tools like XGBoost or Logistic Regression to answer immediate questions, either framed as a regression or a classification problem.
Examples
- Fraudulent transactions.
- Credit risk scoring.
- Predictive maintenance.
- Customer churn.
Data samples
Forecasting
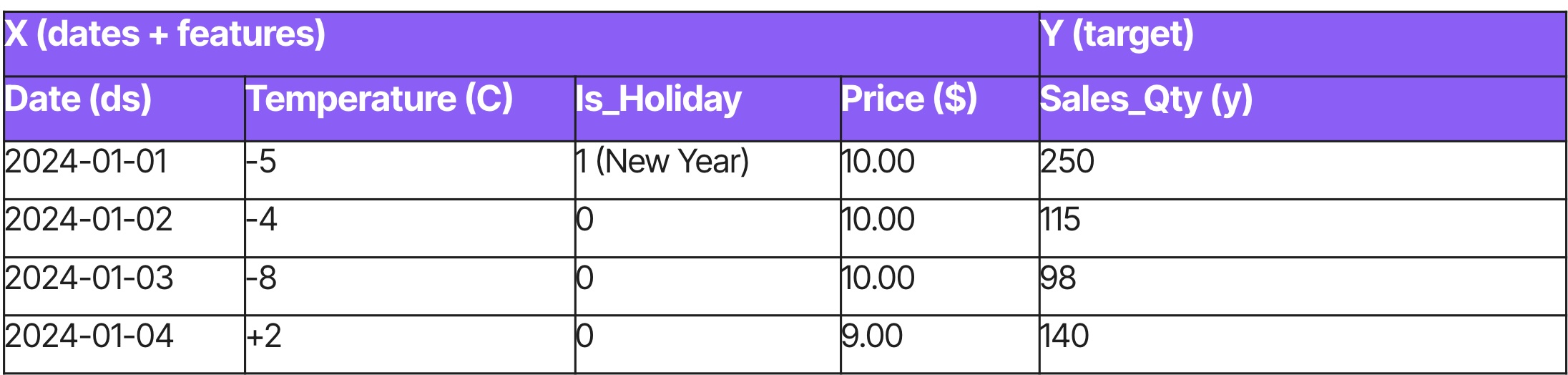
Forecasting utilizes longitudinal data to address questions about the future. It breaks the assumption of independence. Instead, it relies on autocorrelation, where the current state is functionally dependent on previous states. What happened yesterday directly influences what happens today.
This approach is best suited for planning and capacity decisions where the objective is to estimate future volumes over time. The goal is to extend historical patterns into the future to estimate volumes, such as predicting total sales for the upcoming quarter. Because this requires an understanding of sequence and seasonality, it benefits from specialized time-series architectures like LSTMs, or foundation models like Chronos.
Examples
- Monthly sales predictions.
- Weekly inventory demands for SKU.
- Energy load.
Data samples
How to Approach It: A Framework for Delivery
Here is the technical and strategic guidance required to deliver a successful predictive modeling project.
Project Definition
- Scoping: To prevent scope creep, anchor the project in a realistic definition of "good enough." Stakeholders often expect near-perfect predictions. It is your role, as a developer, to define a success metric tied to ROI rather than raw accuracy. If a naive baseline achieves 50%, a model that reaches 60% can be valuable if it improves the bottom line.
- Baseline Definition: Always begin with a heuristic "dumb model" rather than a complex algorithm. This establishes a benchmark. If a sophisticated XGBoost model only beats a simple average by a marginal 1%, it is likely not worth the deployment cost.
Data Preparation
- Data Integrity: The absolute priority is avoiding the "time travel trap"—training on data generated after the prediction point. This creates an illusion of accuracy that vanishes in production. If a business process has a three-month gap between prediction and outcome, your training strategy must mirror this.
- Temporal Continuity: unlike predictive models that handle random gaps, forecasting models demand a strictly continuous timeline (e.g., every day, every hour). You cannot simply skip a missing date; you must explicitly insert it and impute the missing target (often 0). Be warned: if a dataset becomes dominated by zeros, it shifts to an intermittent time series, where the predictive signal is easily drowned out by the noise.
- Destructive Updates: Be cautious of databases that overwrite history with current values (destructive updates). Training on "corrected" data to predict past events is a form of bias that the model cannot replicate in real-time.
- Quality over Quantity: A small, clean dataset with a high predictive signal will consistently outperform a massive, noisy dataset.
Modeling and Evaluation
- Model Complexity: Complexity is a form of technical debt. Elaborate architectures are harder to debug and brittle in production. A straightforward statistical model that achieves 90% of the performance of a deep neural network is often the superior choice because it fails gracefully.
- Evaluation Metrics: Optimizing for accuracy alone is a pitfall. Standard accuracy metrics hide critical trade-offs (e.g., the cost of a false positive vs. a false negative). Use profit curves to assess real-world impact. Furthermore, if you are dealing with intermittent data (many zeros), avoid MAPE, which becomes mathematically undefined (division by zero). In these scenarios, rely on metrics like MASE or RMSE.
- Interpretability: Treat explainability as a core feature. A slightly less accurate model that is explainable (like a Decision Tree) is often preferable to a black-box Neural Network.
- Cross-validation: Avoid look-ahead bias. Random splits fail in predictive analytics because they ignore time correlations. Always use a Time-Series Split (train on Jan-Mar, test on Apr) rather than shuffling the dataset.
Deployment and Monitoring
- Data Drift: The moment a model is deployed, it begins to degrade. Monitor the input data distribution, not just the output. If the average age of users suddenly drops by ten years, it is an early warning system that the model is operating out of distribution.
- Feedback Loop: If a model predicts a user is "not interested" and you stop showing them ads, you create a blind spot. You will never learn if their interests change. Always maintain a control group (e.g., a random 5% of traffic) to measure true lift.
- Cold Start: Have a concrete plan for new customers or products with zero history. Implement a fallback heuristic so the system provides a baseline experience rather than crashing or outputting noise.
Soft Skills and Stakeholder Management
- Managing Expectations: Master the art of under-promising and over-delivering. Never promise "The model will be ready in two weeks" before data discovery. Frame commitments around milestones and discovery phases.
- Communication: When presenting to stakeholders, translate raw accuracy metrics into business impact.
- Documentation: Documentation is your defense against technical amnesia. Record why specific strategic decisions were made (e.g., why a feature was dropped), not just how the code works.
The Data Readiness Checklist
Before giving the green light, ensure the project satisfies these three pillars. If not, the project should be re-scoped or postponed.
A. Data Availability
- Target Variable Existence: Do we have historical labels?
- History Depth: Do we have enough history to cover seasonality? (Minimum 12 months is standard for retail/finance).
- Lag Check: Can we access input data at the moment of prediction? (e.g., If predicting at 9 AM, is the 8 AM data actually in the warehouse, or does it load the next day?)
B. Data Quality
- Continuity Check: Is the timeline strictly continuous? If we have gaps, do we have a strategy to impute them (e.g., filling with 0) without destroying the signal?
- Leakage Audit: Have we removed all features that are generated after the event?
- Bias Check: Is the historical data biased?
C. Implementation & Deployment
- Latency Requirement: Does the prediction need to be real-time (<200ms) or batch (overnight)? Real-time increases engineering cost by 10x.
- Cold Start Strategy: Do we have a fallback rule for new users/products with no history?
- Compute Resources: What is the training/inference environment (cloud/on-prem)?
Conclusion
Predictive Machine Learning is not about building perfect models. It’s about making better decisions under uncertainty. The most successful projects focus less on algorithms and more on data integrity, evaluation strategy, and operational reality. When predictive systems are designed with clear business objectives, realistic baselines, and robust monitoring, they become durable assets rather than fragile experiments. In practice, simplicity, transparency, and discipline consistently outperform complexity.


Did this article start to give you some ideas? We’d love to work with you! Get in touch and let’s discover what we can do together.
-min.jpg)

.png)



